Way2AI · 机器学习之Logistic Regression (二)
TL;DR
Way2AI系列,确保出发去"改变世界"之前,我们已经打下了一个坚实的基础。
接上篇,本文使用PyTorch实现一个简单的逻辑回归。
Get ready
复用前篇的数据准备及预处理工作,这里直接建模。
Model
我们使用PyTorch的Linear layers 来构建与前篇相同的模型。
1 | import torch |
Loss
这里使用交叉熵损失
1 | loss_fn = nn.CrossEntropyLoss() |
在这个任务中,我们将数据的类别权重纳入到损失函数中,以对抗样本的类别不平衡。
1 | # Define Loss |
Metrics
我们将在训练模型时引入准确度来衡量模型的性能,因为仅查看损失值并不是非常直观。
后面的章节会介绍相关指标。
1 | # Accuracy |
Optimizer
与之前介绍的线性回归一样,这里同样使用Adam优化器。
1 | from torch.optim import Adam |
Training
1 | # Convert data to tensors |
Evaluation
首先,我们看看一下测试集的准确率
1 | from sklearn.metrics import accuracy_score |
我们还可以根据其他有意义的指标来评估我们的模型,如精确度和召回率。
$$
accuracy = \frac{TP + FN}{TP + TN + FP + FN}
$$
$$
recall = \frac{TP}{TP + FN}
$$
$$
precision = \frac{TP}{TP + FP}
$$
$$
F1 = 2 * \frac{precision * recall}{precision + recall}
$$
| 参数 | 解释 |
|---|---|
| TP | truly predicted to be positive and were positive |
| TN | truly predicted to negative and where negative |
| FP | falsely predicted to be positive but where negative |
| FN | falsely predicted to be negative but where positive |
格式化指标,以供前端展示
1 | import json |
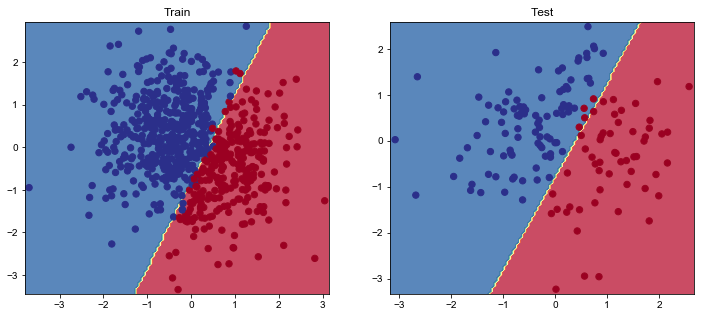
同样的,利用PyTorch实现的逻辑回归模型建模了一个线性决策边界,我们可视化一下结果。
1 | def plot_multiclass_decision_boundary(model, X, y): |
Inference
1 | # Inputs for inference |
Unscaled weights
同样的,我们亦可以逆标准化我们的权重和偏差。
注意到只有$X$被标准化过
$$
\hat{y}_{unscaled} = \sum_{j=1}^k W_{scaled(j)} x_{scaled(j)} + b_{scaled}
$$
已知
$$
\hat{x}_{scaled} = \frac{x_{j} - \overline{x}_{j}}{\sigma_{j}}
$$
于是
$$
\hat{y}_{unscaled} = (b_{scaled} - \sum_{j=1}^k W_{scaled(j)} \frac{\overline{x}_j}{\sigma_{j}}) + \sum_j{\frac{W_{scaled(j)}}{\sigma_j}}x_j
$$
对比公式
$$
\hat{y}_{unscaled} = W_{unscaled} x + b_{unscaled}
$$
便可得知
$$
W_{unscaled} = \frac{W_{scaled(j)}}{\sigma_j}
$$
$$
b_{unscaled} = b_{scaled} - \sum_{j=1}^k W_{unscaled(j)} \overline{x}_j
$$
1 | # Unstandardize weights |
Ending
到这里,我们便完成了PyTorch的逻辑回归任务的介绍。
Citation
1 | @article{madewithml, |
- Blog Link: https://neo1989.net/Way2AI/Way2AI-LogisticRegression-2/
- Copyright Declaration: 转载请声明出处。