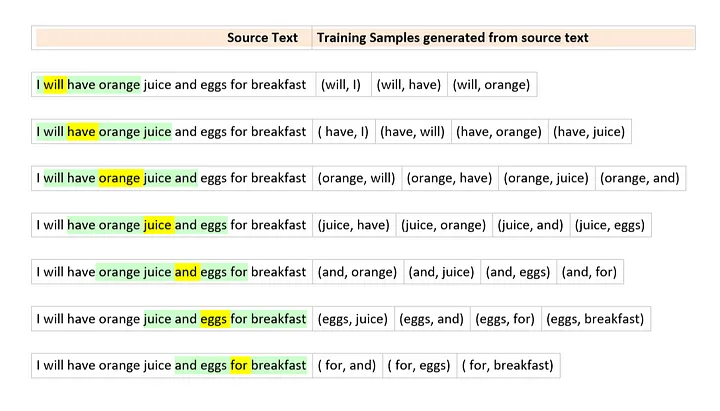
# Split text into sentence tokenizer = nltk.data.load("tokenizers/punkt/english.pickle") book = requests.get("https://s3.mindex.xyz/datasets/harrypotter.txt").content sentences = tokenizer.tokenize(str(book)) print (f"{len(sentences)} sentences")
# Output # 12449 sentences
defpreprocess(text): """Conditional preprocessing on our text.""" # Lower text = text.lower()
# Spacing and filters text = re.sub(r"([-;;.,!?<=>])", r" \1 ", text) # separate punctuation tied to words text = re.sub("[^A-Za-z0-9]+", " ", text) # remove non alphanumeric chars text = re.sub(" +", " ", text) # remove multiple spaces text = text.strip()
# Separate into word tokens text = text.split(" ")
return text
# Preprocess sentences print (sentences[11]) sentences = [preprocess(s) for s in sentences] print (sentences[11])
# Output # Snape nodded, but did not elaborate. # ['snape', 'nodded', 'but', 'did', 'not', 'elaborate']
# Super fast because of optimized C code under the hood ft = FastText(sentences=sentences, vector_size=EMBEDDING_DIM, window=WINDOW, min_count=MIN_COUNT, sg=SKIP_GRAM, negative=NEGATIVE_SAMPLING) print (ft)
# This word doesn't exist so the word2vec model will error out wv.most_similar(positive='scarring', topn=5) # Output # KeyError: "Key 'scarring' not present in vocabulary"
# FastText will use n-grams to embed an OOV word ft.wv.most_similar(positive='scarring', topn=5)