TL;DR
本文简单示范了如何利用CNN处理NLP任务。
CNNs的核心就是利用卷积(滑动)操作来提取数据特征的卷积核(aka kernels, filters,weights, etc.)。它们随机初始化但通过参数共享来提取特征。
Set up
复用《PyTorch实现神经网络的基本套路》 里介绍的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import numpy as npimport pandas as pdimport randomimport torchimport torch.nn as nndef set_seeds (seed=1024 ): """Set seeds for reproducibility.""" np.random.seed(seed) random.seed(seed) touch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.cuda.manual_seed_all(seed) set_seeds(seed=1024 ) cuda = True device = torch.device("cuda" if (torch.cuda.is_available() and cuda) else "cpu" ) torch.set_default_tensor_type({"cuda" : "torch.cuda.FloatTensor" , "cpu" : "torch.FloatTensor" }.get(str (device)))
Load data
我们将在AGNews dataset 这个数据集上完成本次学习任务。这是一份来自4个不同新闻分类120k条新闻标题样本。
1 2 3 4 5 url = "https://s3.mindex.xyz/datasets/news.csv" df = pd.read_csv(url, header=0 ) df = df.sample(frac=1 ).reset_index(drop=True ) df
Preprocessing
首先要做的,是对这些数据进行预处理,手段包括删除停用词、字母小写(英文)、词形还原词干提取、中文分词、正则处理等。
由于我们的任务是纯英文数据,这里使用英文的通用处理方法。中文任务以后再表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import reimport nltkfrom nltk.corpus import stopwordsfrom nltk.stem import PorterStemmernltk.download("stopwords" ) STOPWORDS = stopwords.words("english" ) print (STOPWORDS[:5 ])porter = PorterStemmer() def preprocess (text, stopwords=STOPWORDS ): """Conditional preprocessing on our text unique to our task.""" text = text.lower() pattern = re.compile (r"\b(" + r"|" .join(stopwords) + r")\b\s*" ) text = pattern.sub("" , text) text = re.sub(r"\([^)]*\)" , "" , text) text = re.sub(r"([-;;.,!?<=>])" , r" \1 " , text) text = re.sub("[^A-Za-z0-9]+" , " " , text) text = re.sub(" +" , " " , text) text = text.strip() return text preprocessed_df = df.copy() preprocessed_df.title = preprocessed_df.title.apply(preprocess) print (f"{df.title.values[-1 ]} \n\n{preprocessed_df.title.values[-1 ]} " )
Split data
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import collectionsfrom sklearn.model_selection import train_test_splitTRAIN_SIZE = 0.7 VAL_SIZE = 0.15 TEST_SIZE = 0.15 def train_val_test_split (X, y, train_size ): X_train, X_, y_train,y_ = train_test_split(X, y, train_size=train_size, stratify=y) X_val, X_test, y_val, y_test = train_test_split(X_, y_, train_size=0.5 , stratify=y_) return X_train, X_val, X_test, y_train, y_val, y_test X = preprocessed_df["title" ].values y = preprocessed_df["category" ].values X_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(X=X, y=y, train_size=TRAIN_SIZE) print (f"X_train: {X_train.shape} , y_train: {y_train.shape} " )print (f"X_val: {X_val.shape} , y_val: {y_val.shape} " )print (f"X_test: {X_test.shape} , y_test: {y_test.shape} " )print (f"Sample point: {X_train[0 ]} → {y_train[0 ]} " )
Label encoding
复用《PyTorch实现神经网络的基本套路》 里介绍的 LabelEncoder
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 label_encoder = LabelEncoder() label_encoder.fit(y_train) NUM_CLASSES = len (label_encoder) print (label_encoder.class_to_index)print (f"y_train[0]: {y_train[0 ]} " )y_train = label_encoder.encode(y_train) y_val = label_encoder.encode(y_val) y_test = label_encoder.encode(y_test) print (f"y_train[0]: {y_train[0 ]} " )counts = np.bincount(y_train) class_weights = {i: 1.0 /count for i, count in enumerate (counts)} print (f"counts: {counts} \nweights: {class_weights} " )
Tokenizer
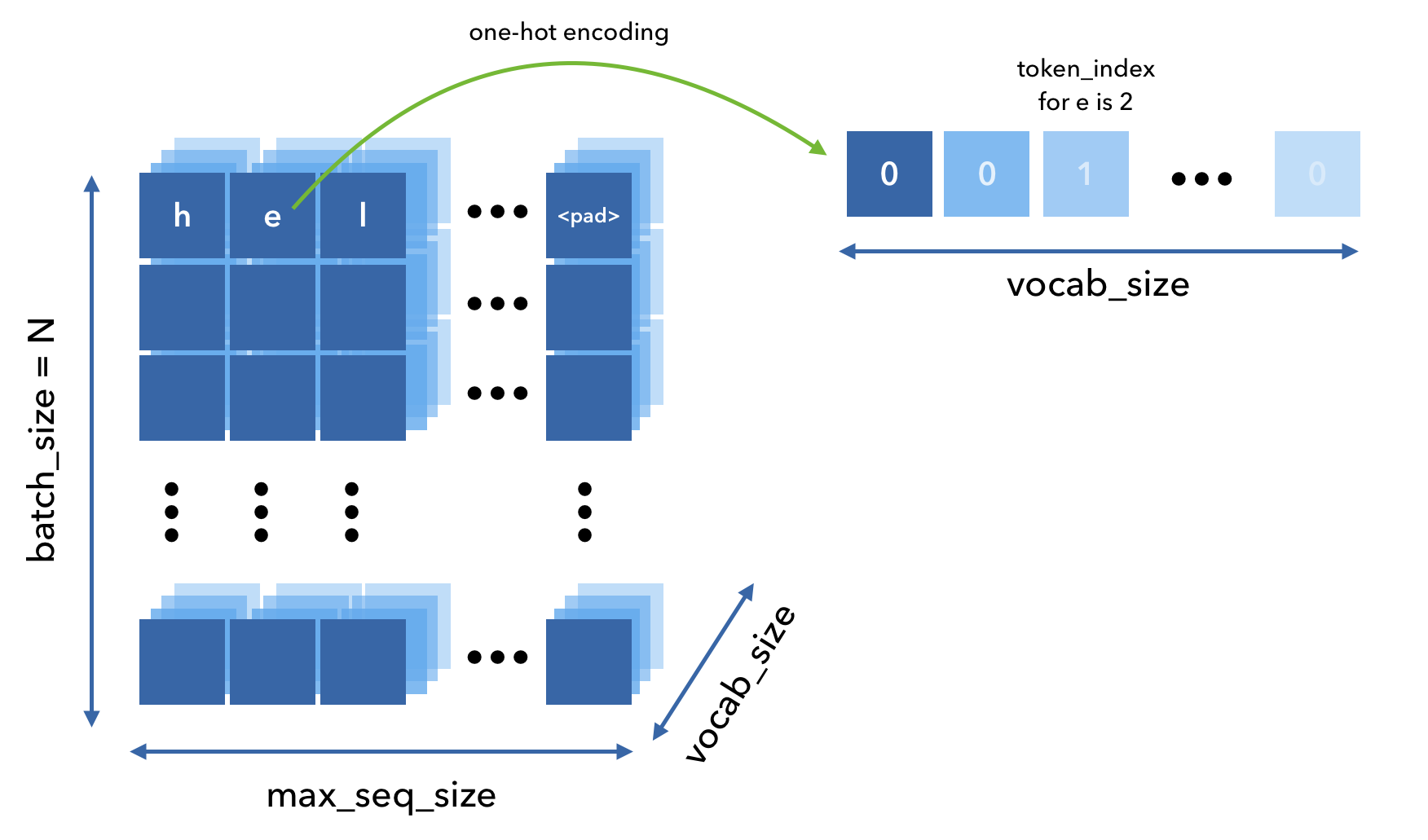
由于任务要处理的是文本,无法直接送给模型。因此我们定义一个Tokenizer来处理文本数据,目的是将文本序列转化成离散的标记(tokens),以便后续的处理和分析。这意味着每个token可以映射到一个唯一的索引,这样我们就可以用一个索引数组(向量)来表示文本序列。而一个token可以是一个字符、一个单词、一个词组等等。
下面是一个示例实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 import jsonfrom collections import Counterfrom more_itertools import takeclass Tokenizer (object ): def __init__ (self, char_level, num_tokens=None , pad_token="<PAD>" , oov_token="<UNK>" , token_to_index=None ): self.char_level = char_level self.separator = "" if self.char_level else " " if num_tokens: num_tokens -= 2 self.num_tokens = num_tokens self.pad_token = pad_token self.oov_token = oov_token self.token_to_index = token_to_index if token_to_index else {pad_token: 0 , oov_token: 1 } self.index_to_token = {v: k for k, v in self.token_to_index.items()} def __len__ (self ): return len (self.token_to_index) def __str__ (self ): return f"<Tokenizer(num_tokens={len (self)} )>" def fit_on_texts (self, texts ): if not self.char_level: texts = [text.split(" " ) for text in texts] all_tokens = [token for text in texts for token in text] counts = Counter(all_tokens).most_common(self.num_tokens) self.min_token_freq = counts[-1 ][1 ] for token, count in counts: index = len (self) self.token_to_index[token] = index self.index_to_token[index] = token return self def texts_to_sequences (self, texts ): sequences = [] for text in texts: if not self.char_level: text = text.split(" " ) sequence = [] for token in text: sequence.append(self.token_to_index.get( token, self.token_to_index[self.oov_token])) sequences.append(np.asarray(sequence)) return sequences def sequences_to_texts (self, sequences ): texts = [] for sequence in sequences: text = [] for index in sequence: text.append(self.index_to_token.get(index, self.oov_token)) texts.append(self.separator.join([token for token in text])) return texts def save (self, fp ): with open (fp, "w" ) as fp: contents = { "char_level" : self.char_level, "oov_token" : self.oov_token, "token_to_index" : self.token_to_index } json.dump(contents, fp, indent=4 , sort_keys=False ) @classmethod def load (cls, fp ): with open (fp, "r" ) as fp: kwargs = json.load(fp=fp) return cls(**kwargs)
本次实验我们限制tokens的数量为500个(停用词已删除),其中包括两个占位的。如果您的计算资源足够,可以使用更大的tokens数量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 tokenizer = Tokenizer(char_level=False , num_tokens=500 ) tokenizer.fit_on_texts(texts=X_train) VOCAB_SIZE = len (tokenizer) print (tokenizer)print (take(10 , tokenizer.token_to_index.items()))print (f"least freq token's freq: {tokenizer.min_token_freq} " )
Ok,接下来将我们文本数据全部token化
1 2 3 4 5 6 7 8 9 10 11 12 13 X_train = tokenizer.texts_to_sequences(X_train) X_val = tokenizer.texts_to_sequences(X_val) X_test = tokenizer.texts_to_sequences(X_test) preprocessed_text = tokenizer.sequences_to_texts([X_train[0 ]])[0 ] print ("Text to indices:\n" f" (preprocessed) → {preprocessed_text} \n" f" (tokenized) → {X_train[0 ]} " )
One-hot encoding
One-hot编码是一种将离散变量表示为二进制向量的技术。它允许我们以一种模型可以理解的方式来表示数据,并且不受token的实际值的影响。
举个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "a" : 0 , "e" : 1 , "i" : 2 , "o" : 3 , "u" : 4 , } [[1 , 0 , 0 , 0 , 0 ], [0 , 0 , 0 , 1 , 0 ], [0 , 0 , 0 , 0 , 1 ]]
我们手动实现一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def to_categorical (seq, num_classes ): """One-hot encode a sequence of tokens.""" one_hot = np.zeros((len (seq), num_classes)) for i, item in enumerate (seq): one_hot[i, item] = 1 return one_hot print (X_train[0 ])print (len (X_train[0 ]))cat = to_categorical(seq=X_train[0 ], num_classes=len (tokenizer)) print (cat)print (cat.shape)
接下来需要将我们的数据进行one-hot编码处理
1 2 3 4 5 vocab_size = len (tokenizer) X_train = [to_categorical(seq, num_classes=vocab_size) for seq in X_train] X_val = [to_categorical(seq, num_classes=vocab_size) for seq in X_val] X_test = [to_categorical(seq, num_classes=vocab_size) for seq in X_test]
Padding
由于我们的数据是不定长的新闻标题,而模型能够处理的是相同形状的数据,所以引入padding来预处理数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def pad_sequences (sequences, max_seq_len=0 ): """Pad sequences to max length in sequence.""" max_seq_len = max (max_seq_len, max (len (sequence) for sequence in sequences)) num_classes = sequences[0 ].shape[-1 ] padded_sequences = np.zeros((len (sequences), max_seq_len, num_classes)) for i, sequence in enumerate (sequences): padded_sequences[i][:len (sequence)] = sequence return padded_sequences print (X_train[0 ].shape, X_train[1 ].shape, X_train[2 ].shape)padded = pad_sequences(X_train[0 :3 ]) print (padded.shape)
Dataset
一如上篇文章里介绍的,我们需要把数据放在 Dataset 中,并使用 DataLoader 来有效地创建用于训练和验证的批次。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 FILTER_SIZE = 1 class Dataset (torch.utils.data.Dataset): def __init__ (self, X, y, max_filter_size ): self.X = X self.y = y self.max_filter_size = max_filter_size def __len__ (self ): return len (self.y) def __str__ (self ): return f"<Dataset(N={len (self)} )>" def __getitem__ (self, index ): X = self.X[index] y = self.y[index] return [X, y] def collate_fn (self, batch ): """Processing on a batch.""" batch = np.array(batch) X = batch[:, 0 ] y = batch[:, 1 ] X = pad_sequences(X, max_seq_len=self.max_filter_size) X = torch.FloatTensor(X.astype(np.int32)) y = torch.LongTensor(y.astype(np.int32)) return X, y def create_dataloader (self, batch_size, shuffle=False , drop_last=False ): return torch.utils.data.DataLoader( dataset=self, batch_size=batch_size, collate_fn=self.collate_fn, shuffle=shuffle, drop_last=drop_last, pin_memory=True ) train_dataset = Dataset(X=X_train, y=y_train, max_filter_size=FILTER_SIZE) val_dataset = Dataset(X=X_val, y=y_val, max_filter_size=FILTER_SIZE) test_dataset = Dataset(X=X_test, y=y_test, max_filter_size=FILTER_SIZE) print ("Datasets:\n" f" Train dataset:{train_dataset.__str__()} \n" f" Val dataset: {val_dataset.__str__()} \n" f" Test dataset: {test_dataset.__str__()} \n" "Sample point:\n" f" X: {test_dataset[0 ][0 ]} \n" f" y: {test_dataset[0 ][1 ]} " ) batch_size = 64 train_dataloader = train_dataset.create_dataloader(batch_size=batch_size) val_dataloader = val_dataset.create_dataloader(batch_size=batch_size) test_dataloader = test_dataset.create_dataloader(batch_size=batch_size) batch_X, batch_y = next (iter (test_dataloader)) print ("Sample batch:\n" f" X: {list (batch_X.size())} \n" f" y: {list (batch_y.size())} \n" "Sample point:\n" f" X: {batch_X[0 ]} \n" f" y: {batch_y[0 ]} " )
CNN
接下来呢要进入本篇的重点,CNN了。
下面这个简单的示例里,我们随机给出了N个样本,每个样本有8个token,而我们的词表大小是10个。
也就意味着,我们inputs的形状是 (N, 8, 10)
但需要注意的是,当我使用PyTorch处理CNN时,通道数需要在第二个维度,也就意味着,在这个例子里,我们的inputs的形状得是 (N, 10, 8)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import mathimport torchimport torch.nn as nnimport torch.nn.functional as Fbatch_size = 64 max_seq_len = 8 vocab_size = 10 x = torch.randn(batch_size, max_seq_len, vocab_size) print (f"X: {x.shape} " )x = x.transpose(1 , 2 ) print (f"X: {x.shape} " )
Filters
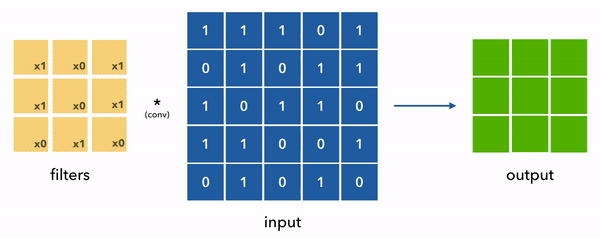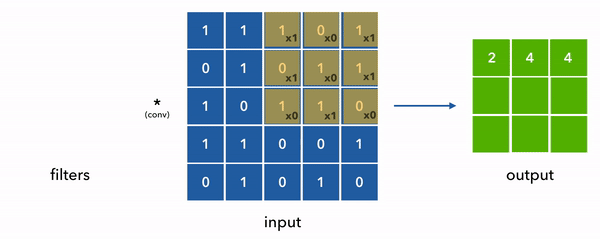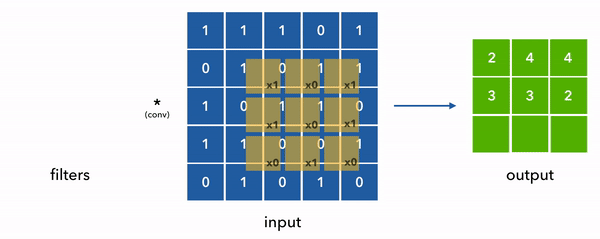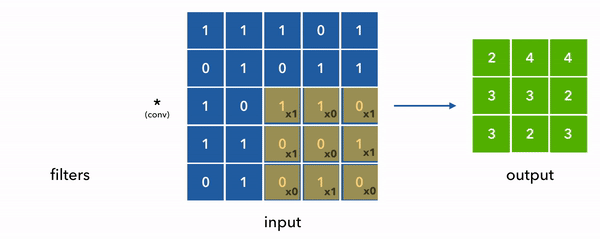
在下面的动画中,我们将卷积核和输入简化成2D,以便于可视化,而且实际上值并不总是是0或1,而是任意的浮点数。
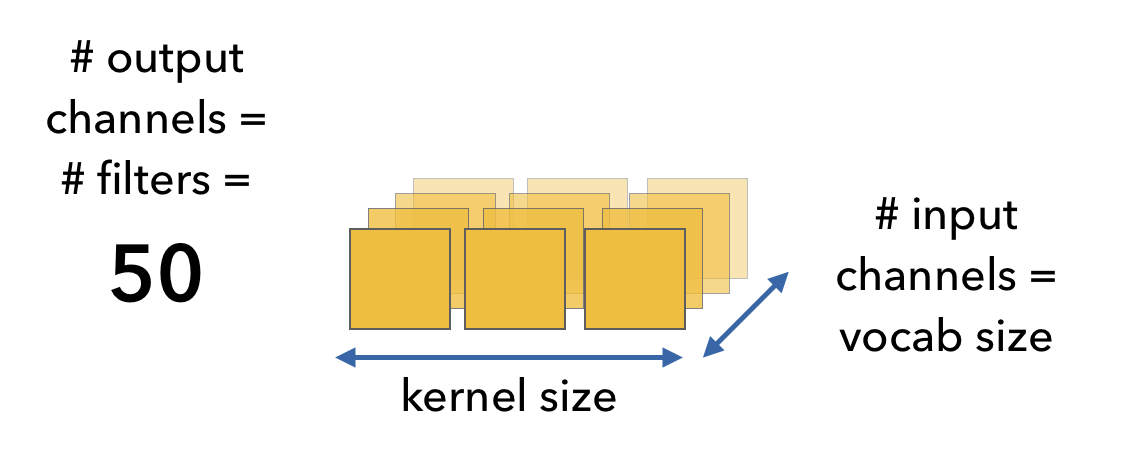
现在回到我们的示例数据,单个样本的形状是(8, 10) [max_seq_len, vocab_size],然后我们考虑用50个形状是(1, 3)的一维卷积来提取数据的特征,由于我们的数据的通道数是10 (num_channels = vocab_size = one_hot_size = 10), 这边意味着这个卷积核的形状便是 (3, 10, 50) [kernel_size, vocab_size, num_filters]
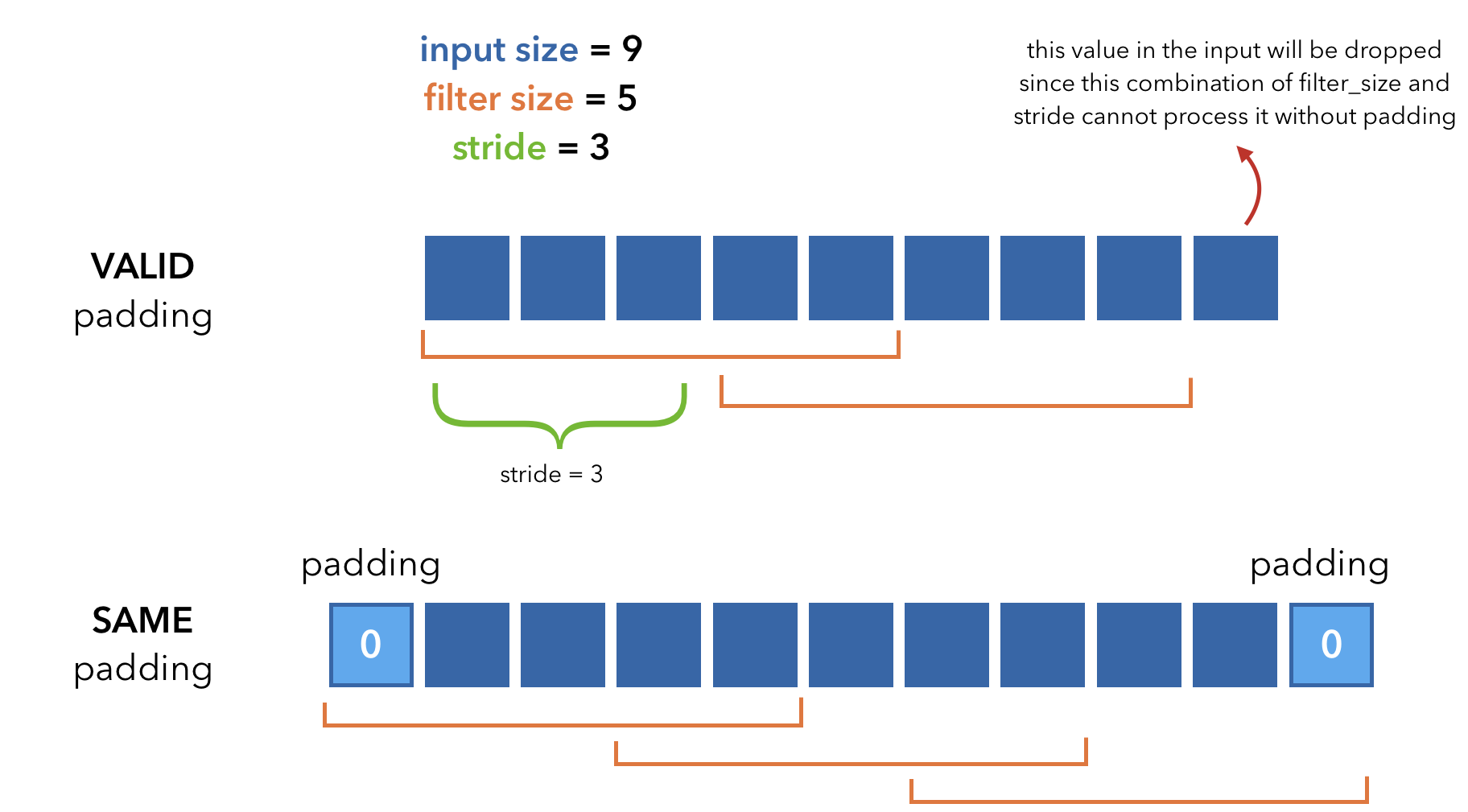
这里有两个关键的概念,步长(stride) 和 填充(padding). 详见下图
这里采用一维卷积Conv1D 来处理示例数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 num_filters = 50 filter_size = 3 stride = 1 padding = 0 conv1 = nn.Conv1d(in_channels=vocab_size, out_channels=num_filters, kernel_size=filter_size, stride=stride, padding=padding, padding_mode="zeros" ) print (f"conv: {conv1.weight.shape} " )z = conv1(x) print (f"z: {z.shape} " )
如你所见,我们输入数据max_seq_len=8,而经过卷积后的output的长度却是6。如果需要保证长度一致,那么就需要引入padding了。
如果P不是一个整数,考虑向上取整(math.ceil)在右侧填充。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 num_filters = 50 filter_size = 3 stride = 1 padding = 0 conv = nn.Conv1d(in_channels=vocab_size, out_channels=num_filters, kernel_size=filter_size, stride=stride, padding=padding, padding_mode="zeros" ) print (f"conv: {conv.weight.shape} " )padding_left = int ((conv.stride[0 ]*(max_seq_len-1 ) - max_seq_len + filter_size) / 2 ) padding_right =int (math.ceil((conv.stride[0 ]*(max_seq_len-1 ) - max_seq_len + filter_size) / 2 )) print (f"padding: {(padding_left, padding_right)} " )z = conv(F.pad(x, (padding_left, padding_right))) print (f"z: {z.shape} " )
未来我们会探索更高维度的卷积层。包括使用Conv2D来处理3D数据(图像、字符级别文本等),使用Conv3D来处理4D数据(视频、时间序列数据等)
Pooling
池化是一种用于简化下游计算的方法,通过将高维特征图总结为较低维特征图来减少冗余信息。在卷积滤波器对输入进行处理后产生的特征映射中,由于卷积和重叠的性质,会存在大量的冗余信息。池化操作可以采用最大值或平均值等方式。下面是一个池化的示例:假设来自卷积层的输出是4x4的特征图,我们使用2x2的最大池化过滤器进行处理。
在这个例子里,我们使用MaxPool1D 取一个max值。
1 2 3 4 5 6 pool_output = F.max_pool1d(z, z.size(2 )) print (f"Size: {pool_output.shape} " )
Batch normalization
在构建模型前,需要讨论的最后一个主题便是batch normalization . 它是一种对来自前一层激活的标准化操作,使其均值为0,标准差为1。
在以前的笔记本中,我们对输入进行标准化,以便模型能够更快地进行优化,并提高学习率。这里采用相同的概念,但我们在重复的前向传递过程中保持标准化的值,以进一步帮助优化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 batch_norm = nn.BatchNorm1d(num_features=num_filters) z = batch_norm(conv(x)) print (f"z: {z.shape} " )print (f"mean: {torch.mean(conv(x)):.2 f} , std: {torch.std(conv(x)):.2 f} " )print (f"mean: {torch.mean(z):.2 f} , std: {torch.std(z):.2 f} " )
Modling
Model
可视化一下模型的前向传播.
首先对输入tokenizer化 (batch_size, max_seq_len)
然后,one-hot编码 (batch_size, max_seq_len, vocab_size)
接下来,使用filters(filter_size, vocab_size, num_filter)进行卷积,然后批归一化。这里我们的filters相当于一个n-gram检测器。
紧跟着,应用max polling,从特征图中提取最相关信息
再接一个含dropout的全连接层
最后再一个softmax全连接层以输出最终的类别概率
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import mathimport torch.nn.functional as FNUM_FILTERS = 50 HIDDEN_DIM = 100 DROPOUT_P = 0.1 class CNN (nn.Module): def __init__ (self, vocab_size, num_filters, filter_size, hidden_dim, dropout_p, num_classes ): super (CNN, self).__init__() self.filter_size = filter_size self.conv = nn.Conv1d( in_channels=vocab_size, out_channels=num_filters, kernel_size=filter_size, stride=1 , padding=0 , padding_mode='zeros' ) self.batch_norm = nn.BatchNorm1d(num_features=num_filters) self.fc1 = nn.Linear(num_filters, hidden_dim) self.dropout = nn.Dropout(dropout_p) self.fc2 = nn.Linear(hidden_dim, num_classes) def forward (self, inputs, channel_first=False , ): x_in, = inputs if not channel_first: x_in = x_in.transpose(1 , 2 ) max_seq_len = x_in.shape[2 ] padding_left = int ((self.conv.stride[0 ]*(max_seq_len-1 ) - max_seq_len + self.filter_size)/2 ) padding_right = int (math.ceil((self.conv.stride[0 ]*(max_seq_len-1 ) - max_seq_len + self.filter_size)/2 )) z = self.conv(F.pad(x_in, (padding_left, padding_right))) z = F.max_pool1d(z, z.size(2 )).squeeze(2 ) z = self.fc1(z) z = self.dropout(z) z = self.fc2(z) return z model = CNN(vocab_size=VOCAB_SIZE, num_filters=NUM_FILTERS, filter_size=FILTER_SIZE, hidden_dim=HIDDEN_DIM, dropout_p=DROPOUT_P, num_classes=NUM_CLASSES) model = model.to(device) print (model.named_parameters)
Training
接下来,利用到《PyTorch实现神经网络的基本套路》 里介绍到Trainer类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 from torch.optim import AdamLEARNING_RATE = 1e-3 PATIENCE = 5 NUM_EPOCHS = 10 class Trainer (object ): def __init__ (self, model, device, loss_fn=None , optimizer=None , scheduler=None ): self.model = model self.device = device self.loss_fn = loss_fn self.optimizer = optimizer self.scheduler = scheduler def train_step (self, dataloader ): """Train step.""" self.model.train() loss = 0.0 for i, batch in enumerate (dataloader): batch = [item.to(self.device) for item in batch] inputs, targets = batch[:-1 ], batch[-1 ] self.optimizer.zero_grad() z = self.model(inputs) J = self.loss_fn(z, targets) J.backward() self.optimizer.step() loss += (J.detach().item() - loss) / (i + 1 ) return loss def eval_step (self, dataloader ): """Validation or test step.""" self.model.eval () loss = 0.0 y_trues, y_probs = [], [] with torch.inference_mode(): for i, batch in enumerate (dataloader): batch = [item.to(self.device) for item in batch] inputs, y_true = batch[:-1 ], batch[-1 ] z = self.model(inputs) J = self.loss_fn(z, y_true).item() loss += (J - loss) / (i + 1 ) y_prob = F.softmax(z).cpu().numpy() y_probs.extend(y_prob) y_trues.extend(y_true.cpu().numpy()) return loss, np.vstack(y_trues), np.vstack(y_probs) def predict_step (self, dataloader ): """Prediction step.""" self.model.eval () y_probs = [] with torch.inference_mode(): for i, batch in enumerate (dataloader): inputs, targets = batch[:-1 ], batch[-1 ] z = self.model(inputs) y_prob = F.softmax(z).cpu().numpy() y_probs.extend(y_prob) return np.vstack(y_probs) def train (self, num_epochs, patience, train_dataloader, val_dataloader ): best_val_loss = np.inf for epoch in range (num_epochs): train_loss = self.train_step(dataloader=train_dataloader) val_loss, _, _ = self.eval_step(dataloader=val_dataloader) self.scheduler.step(val_loss) if val_loss < best_val_loss: best_val_loss = val_loss best_model = self.model _patience = patience else : _patience -= 1 if not _patience: print ("Stopping early!" ) break print ( f"Epoch: {epoch+1 } | " f"train_loss: {train_loss:.5 f} , " f"val_loss: {val_loss:.5 f} , " f"lr: {self.optimizer.param_groups[0 ]['lr' ]:.2 E} , " f"_patience: {_patience} " ) return best_model
定义必要的组件,然后开始训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class_weights_tensor = torch.Tensor(list (class_weights.values())).to(device) loss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor) optimizer = Adam(model.parameters(), lr=LEARNING_RATE) scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau( optimizer, mode="min" , factor=0.1 , patience=3 ) trainer = Trainer( model=model, device=device, loss_fn=loss_fn, optimizer=optimizer, scheduler=scheduler) best_model = trainer.train( NUM_EPOCHS, PATIENCE, train_dataloader, val_dataloader)
Evaluaton
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import jsonfrom pathlib import Pathfrom sklearn.metrics import precision_recall_fscore_supportdef get_metrics (y_true, y_pred, classes ): """Per-class performance metrics.""" performance = {"overall" : {}, "class" : {}} metrics = precision_recall_fscore_support(y_true, y_pred, average="weighted" ) performance["overall" ]["precision" ] = metrics[0 ] performance["overall" ]["recall" ] = metrics[1 ] performance["overall" ]["f1" ] = metrics[2 ] performance["overall" ]["num_samples" ] = np.float64(len (y_true)) metrics = precision_recall_fscore_support(y_true, y_pred, average=None ) for i in range (len (classes)): performance["class" ][classes[i]] = { "precision" : metrics[0 ][i], "recall" : metrics[1 ][i], "f1" : metrics[2 ][i], "num_samples" : np.float64(metrics[3 ][i]), } return performance test_loss, y_true, y_prob = trainer.eval_step(dataloader=test_dataloader) y_pred = np.argmax(y_prob, axis=1 ) performance = get_metrics( y_true=y_test, y_pred=y_pred, classes=label_encoder.classes) print (json.dumps(performance["overall" ], indent=2 ))
保存一些必要的模型数据,以供后续能够完整的加载和使用。
1 2 3 4 5 6 7 8 dir = Path("cnn" )dir .mkdir(parents=True , exist_ok=True )label_encoder.save(fp=Path(dir , "label_encoder.json" )) tokenizer.save(fp=Path(dir , 'tokenizer.json' )) torch.save(best_model.state_dict(), Path(dir , "model.pt" )) with open (Path(dir , 'performance.json' ), "w" ) as fp: json.dump(performance, indent=2 , sort_keys=False , fp=fp)
Inference
接下来看看如何利用模型进行新的推理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 device = torch.device("cpu" ) label_encoder = LabelEncoder.load(fp=Path(dir , "label_encoder.json" )) tokenizer = Tokenizer.load(fp=Path(dir , 'tokenizer.json' )) model = CNN( vocab_size=VOCAB_SIZE, num_filters=NUM_FILTERS, filter_size=FILTER_SIZE, hidden_dim=HIDDEN_DIM, dropout_p=DROPOUT_P, num_classes=NUM_CLASSES) model.load_state_dict(torch.load(Path(dir , "model.pt" ), map_location=device)) model.to(device) trainer = Trainer(model=model, device=device) text = "China’s economic recovery fades as services, factory activity show weakness" sequences = tokenizer.texts_to_sequences([preprocess(text)]) print (tokenizer.sequences_to_texts(sequences))X = [to_categorical(seq, num_classes=len (tokenizer)) for seq in sequences] y_filler = label_encoder.encode([label_encoder.classes[0 ]]*len (X)) dataset = Dataset(X=X, y=y_filler, max_filter_size=FILTER_SIZE) dataloader = dataset.create_dataloader(batch_size=batch_size) y_prob = trainer.predict_step(dataloader) y_pred = np.argmax(y_prob, axis=1 ) print (label_encoder.decode(y_pred))
推理结果是 “China’s economic recovery fades as services, factory activity show weakness” 这篇文章属于 “Business” 这个分类,符合预期。
我们来看一下这个case的具体概率分布
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def get_probability_distribution (y_prob, classes ): """Create a dict of class probabilities from an array.""" results = {} for i, class_ in enumerate (classes): results[class_] = np.float64(y_prob[i]) sorted_results = {k: v for k, v in sorted ( results.items(), key=lambda item: item[1 ], reverse=True )} return sorted_results prob_dist = get_probability_distribution(y_prob=y_prob[0 ], classes=label_encoder.classes) print (json.dumps(prob_dist, indent=2 ))
Ending
本篇给出了一个使用CNN对文本进行分类的完整示例,有很多细节需要深入学习。
但无论如何,先跑起来再说,在战斗中学习战斗。