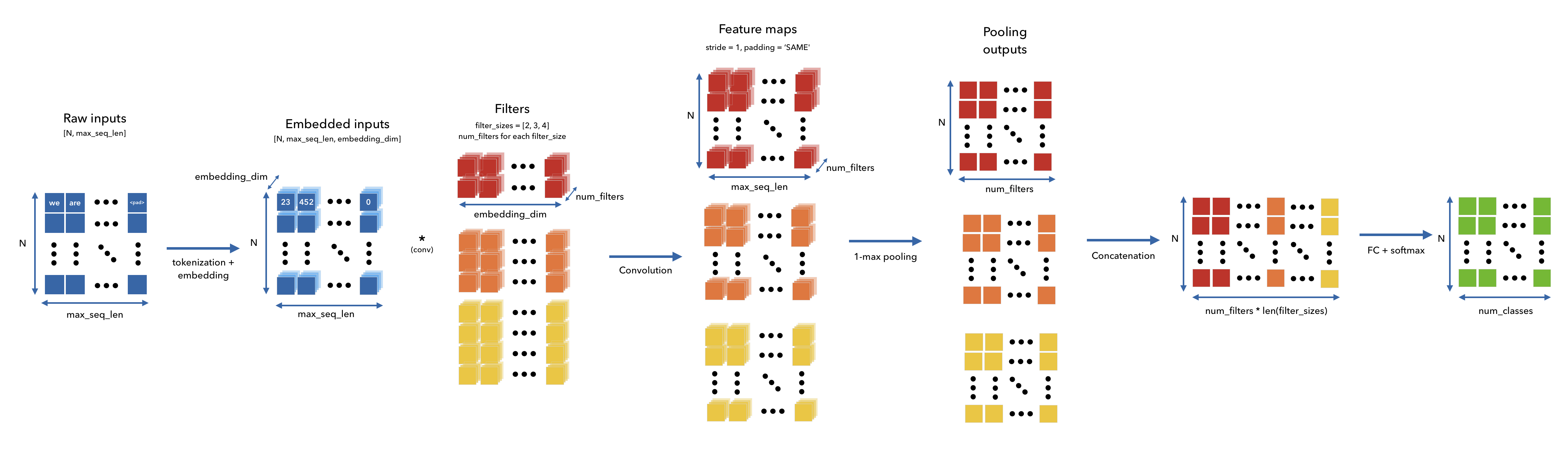
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
| import json
from sklearn.metrics import precision_recall_fscore_support
from torch.optim import Adam
NUM_FILTERS = 50
LEARNING_RATE = 1e-3
PATIENCE = 5
NUM_EPOCHS = 10
class Trainer(object):
def __init__(self, model, device, loss_fn=None, optimizer=None, scheduler=None):
self.model = model
self.device = device
self.loss_fn = loss_fn
self.optimizer = optimizer
self.scheduler = scheduler
def train_step(self, dataloader):
"""Train step."""
self.model.train()
loss = 0.0
for i, batch in enumerate(dataloader):
batch = [item.to(self.device) for item in batch]
inputs, targets = batch[:-1], batch[-1]
self.optimizer.zero_grad()
z = self.model(inputs)
J = self.loss_fn(z, targets)
J.backward()
self.optimizer.step()
loss += (J.detach().item() - loss) / (i + 1)
return loss
def eval_step(self, dataloader):
"""Validation or test step."""
self.model.eval()
loss = 0.0
y_trues, y_probs = [], []
with torch.inference_mode():
for i, batch in enumerate(dataloader):
batch = [item.to(self.device) for item in batch]
inputs, y_true = batch[:-1], batch[-1]
z = self.model(inputs)
J = self.loss_fn(z, y_true).item()
loss += (J - loss) / (i + 1)
y_prob = F.softmax(z).cpu().numpy()
y_probs.extend(y_prob)
y_trues.extend(y_true.cpu().numpy())
return loss, np.vstack(y_trues), np.vstack(y_probs)
def predict_step(self, dataloader):
"""Prediction step."""
self.model.eval()
y_probs = []
with torch.inference_mode():
for i, batch in enumerate(dataloader):
inputs, targets = batch[:-1], batch[-1]
z = self.model(inputs)
y_prob = F.softmax(z).cpu().numpy()
y_probs.extend(y_prob)
return np.vstack(y_probs)
def train(self, num_epochs, patience, train_dataloader, val_dataloader):
best_val_loss = np.inf
for epoch in range(num_epochs):
train_loss = self.train_step(dataloader=train_dataloader)
val_loss, _, _ = self.eval_step(dataloader=val_dataloader)
self.scheduler.step(val_loss)
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = self.model
_patience = patience
else:
_patience -= 1
if not _patience:
print("Stopping early!")
break
print(
f"Epoch: {epoch+1} | "
f"train_loss: {train_loss:.5f}, "
f"val_loss: {val_loss:.5f}, "
f"lr: {self.optimizer.param_groups[0]['lr']:.2E}, "
f"_patience: {_patience}"
)
return best_model
def get_metrics(y_true, y_pred, classes):
"""Per-class performance metrics."""
performance = {"overall": {}, "class": {}}
metrics = precision_recall_fscore_support(y_true, y_pred, average="weighted")
performance["overall"]["precision"] = metrics[0]
performance["overall"]["recall"] = metrics[1]
performance["overall"]["f1"] = metrics[2]
performance["overall"]["num_samples"] = np.float64(len(y_true))
metrics = precision_recall_fscore_support(y_true, y_pred, average=None)
for i in range(len(classes)):
performance["class"][classes[i]] = {
"precision": metrics[0][i],
"recall": metrics[1][i],
"f1": metrics[2][i],
"num_samples": np.float64(metrics[3][i]),
}
return performance
|