LangChain | 快速释放LLM的能力 (一)
什么是LangChain
其实就是用于开发基于LLM应用程序的开发框架。
一个强大的应用程序肯定不是只去调用LLM的API,于是LangChain便提供了两个核心的能力:
- 有数据意识:将LLM与其他数据源连接起来
- 掌握主动权:允许LLM同运行环境交互

LangChain的组件
LangChain提供了模块化抽象,用于处理与语言模型相关的组件。LangChain还拥有所有这些抽象的实现集合。这些组件被设计成易于使用,无论您是否使用LangChain框架的其余部分。
Models
LangChain提供了各种不同类型的模型,方便集成和使用。如 LLMs、Chat Models、Text Embedding Models。
Prompts
如你所知,跟模型打交道的方式便是prompt。通常prompt很少是硬编码的,而是通过多个组件搭建起来的。LangChain提供了多个类和方法,使的结合PromptTemplate构建prompts变得容易。
Chains
对于一些简单的应用来说,孤立地使用LLM是没有问题的,但许多更复杂的应用需要将LLM串联起来。LangChain提供了标准的接口,可以轻松的创建和管理链,以便更好的控制模型的输出。
Agents
有些应用不仅需要一个预先确定的调用LLM/其他工具的链,而且可能需要一个取决于用户输入的未知链。在这些类型的链中,有一个 “代理”,它可以访问一整套的工具。根据用户的输入,代理可以决定调用这些工具中的哪个(如果有的话)。
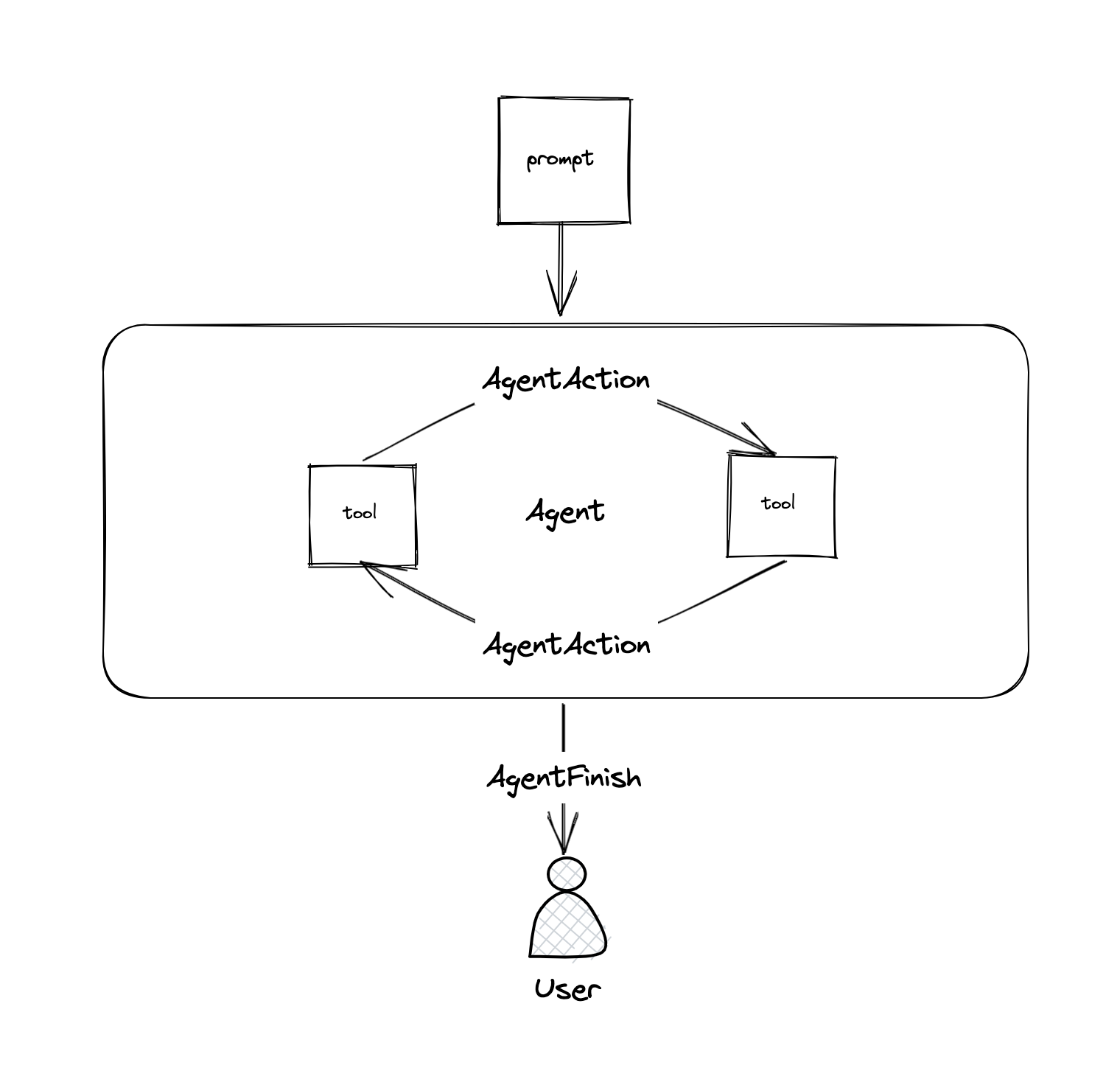
Memory
默认情况下,链和代理是无状态的,这意味着它们会独立处理每个传入的查询(正如底层的LLM和聊天模型)。在一些应用中(聊天机器人就是一个很好的例子),记住以前的互动是非常重要的,无论是短期的还是长期的。LangChain提供了方便的Memory组件和简单的方法以集成到应用程序中。
Indexes
索引指的是结构化文件的方法,以便LLM能够与它们进行最好的交互。
使用索引通常是在检索这一步发生的。即返回与用户的输入最相关的文档。LangChain支持的主要索引和检索类型是围绕着向量数据库进行的。
这部分包含的模块有:
- Document Loaders: 文档加载器,可以从各种源头加载文档
- Text Splitters: 文本分割
- VectorStores:向量存储
- Retrievers:检索
LangChain实战
基本的介绍如上,详细内容请参考官方文档,LearnByDoing才是正经事。
一个很简单的需求,对任意文章进行总结并输出。核心代码及部分注释如下, 10行代码搞定长文本总结:
1 | # 相关依赖 |
于是便可以很方便的集成进任意应用程序了。
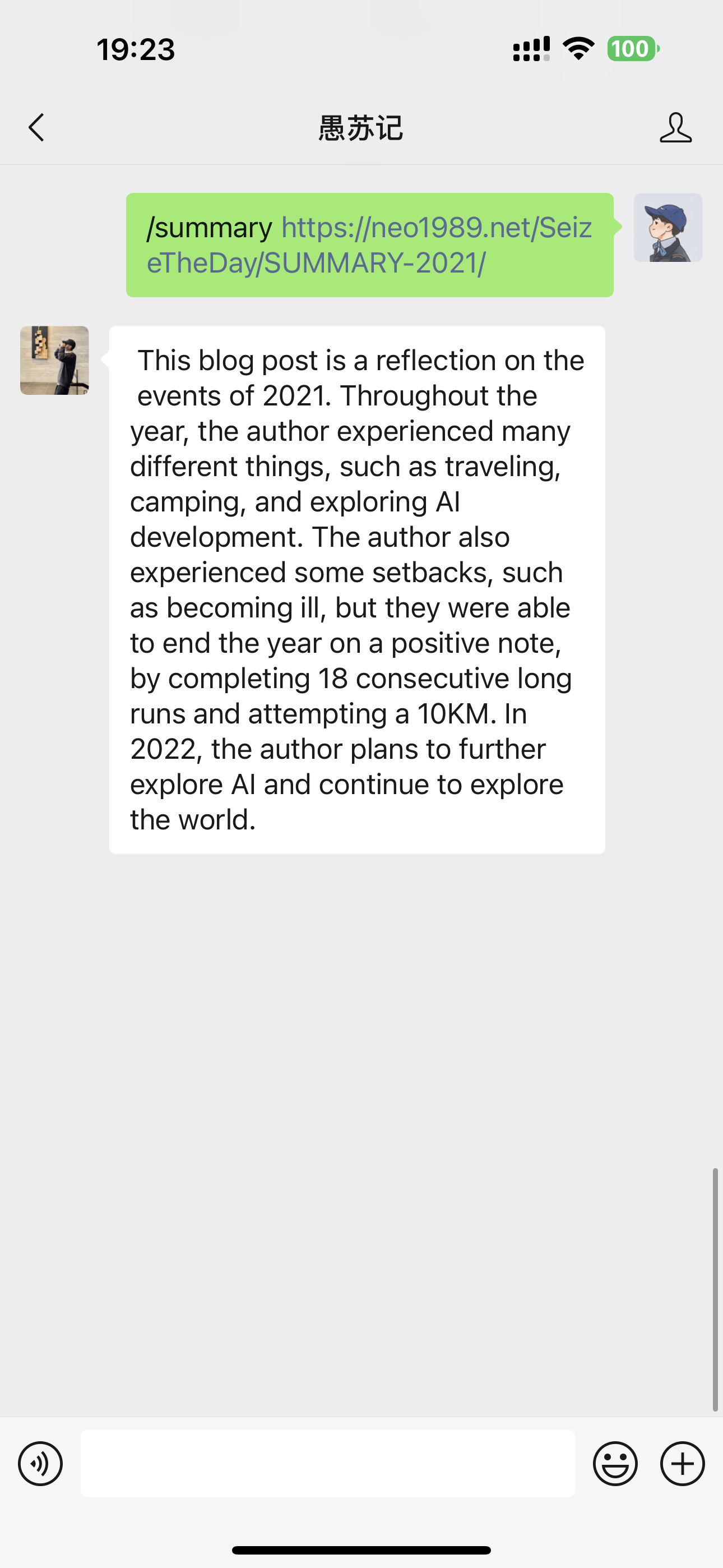
结尾
一个简单的示例,但足以体现LLM的强大以及LangChain的便捷。接下来笔者将尝试在更复杂的应用场景下使用LangChain解决更复杂的问题,Peace out。
- Blog Link: https://neo1989.net/Way2AI/Way2AI-langchain-1/
- Copyright Declaration: 转载请声明出处。