LangChain | 快速释放LLMs的能力 (二)
TL;DR
本文介绍了一种方法,让LLM拥有了学习新知识的能力。
结果展示
LLM的训练是通过大量已有的数据进行学习,由于训练的难度和高额的成本,通常情况它是无法知道最新的时事的,于是它会胡编乱造,也就是是所谓的“幻觉”。如下图所示:
而通过提供资料让它学习,比如作者提供了以下两篇关于星火大模型的新闻稿给它学习:
于是它便能很好的回答相关的问题了。如下图所示:

如何实现
上一篇文章已经介绍了利用LangChain的基本操作实现了一个对任意文本进行总结的小应用。
本篇便是在前一篇的基础上引入了embedding 和 vectorstore 这两个核心能力来实现上述能力。
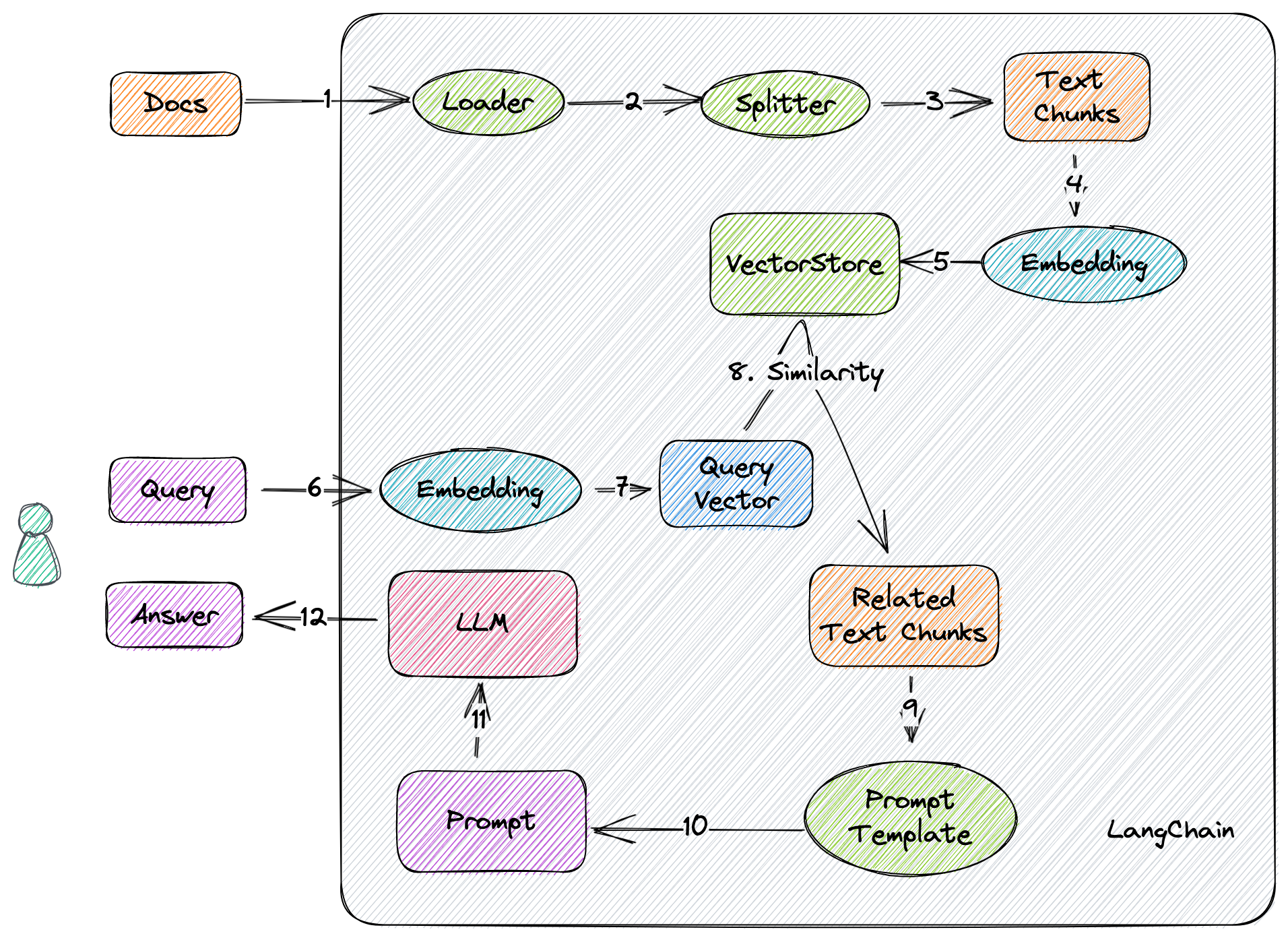
先说一下伪代码,流程如下图所示:
- 加载文档
- 将文档分割成文本块
- 对文本块进行
Embedding - 将上述结果,也就是
Vectors,存到向量数据库中 - 对用户的
Query进行Embedding, 生成Query Vector - 在向量数据库中,利用向量similarity查询出 相关的文本块
- 将上述文本块,套上
Prompt Template,生成最终的Prompt - 丢给
LLM,得到回答
接下来看看LangChain是如何便捷的实现上述功能的。核心代码如下:
1 | from langchain import OpenAI |
不超过10行的核心代码,是不是有手就会?
什么是Embedding
这里涉及到一点NLP的基础知识。
对于给定的一段自然语言文本,第一件事就是将其token化。所谓token就是分割出的一个字或一个词(中文场景)。
- 给定:星火认知大模型是什么
- 按字:星/火/认/知/大/模/型/是/什/么
- 按词:星火/认知/大模型/是/什么
当然还有其它的分割算法,这里按下不表。
Token化之后,如何表示呢,我们知道计算机只能处理数字,所以聪明的先驱们发明了利用一个包含很多小数的数组(也就是一组稠密向量)来表示文本。 Embedding 就是把文本变成向量的过程。
参考OpenAI官方文档 ,Embeddings通常被用于以下场景:
- 搜索(对结果集进行相关性排序)
- 聚类(对文本按照相关性进行分组)
- 分类(对文本按照标签相似度进行分类)
- 推荐(优先推荐相似度高的item)
- 异常检测(识别出相似度小的异常)
- 多样性衡量(对相似度的分布进行分析)
那相似度是如何衡量的?就是计算两个向量之间的距离。距离近相关度高,距离远相关度低,就是这样。
什么是VectorStore
顾名思义,向量数据库就是用来存储,检索,分析向量的数据库。
LangChain提供了非常多的选择,具体请参考文档。
本文示例中的Chroma便是其中一种轻量级的,最近拿了$18M的种子轮。
尾声
另一个简单的示例,看起来已经可以拿去干点什么了。但LangChain的能力不止如此,我们下一篇再看。
Peace out。
- Blog Link: https://neo1989.net/Way2AI/Way2AI-langchain-2/
- Copyright Declaration: 转载请声明出处。