ChatGPT核心技术的进化之路
我们面临这样一个时代的机会。它既是机会,也是挑战。
TL;DR
本文简单梳理了GPT系列的核心工作,从GPT-1到InstructGPT,帮助理解GPT的发展过程。
GPT-1 | 2018
GPT-1 这篇论文提出了“Unsupervised pre-training + Supervised fine-tuning”核心架构,即首先使用大量未标记的文本数据来训练语言模型,然后使用标记数据来微调模型,以便更好地完成特定的判别性任务。
在 GPT 出现之前,NLP 的无监督预训练方法确实很长一段时间都是基于 WordVec 的模型,如 CBOW 和 SkipGram 等。这些模型主要的目的是通过在上下文中共现的词汇之间建立近似的距离关系,从而对自然语言进行表示和分析。
但词向量的模型的主要局限是一个词的向量表示没有考虑在不同的上下文环境里词的含义不同。 因此后续进化出了模型如 ELMo,使用双向 LSTM 对句子建模,得到前向和后向两种特征表示,然后将这两种特征表示拼接起来,作为最终的词向量表示,从而能够较好的处理多义词问题。
然而 ELMo 模型存在计算开销大,对上下文建模和长程依赖较弱,并且本身只能获得句子语义表示等一定的缺陷与局限性。 于是 Transformer 崛起,BERT 和 GPT 便是基于 Transformer 的杰出改进成果。
BERT 在训练过程中采用了 Masked Language Model(MLM) 和 Next Sentence Prediction(NSP) 任务使得两个方向的上下文信息保持一致,以更好的捕捉全局的语义信息。
区别于 BERT,GPT 的无监督预训练阶段,使用的是多层 Transformer Decoder,在对某个位置 i 的 token 进行预测时,利用 i 之前的所有 token 的信息输入 Transformer 进行编码,输出一个条件概率分布来预测 i 位置的 token.

在完成 GPT 的预训练,就进入有监督微调阶段。在特定的任务中使用标记数据微调模型,见下图右.
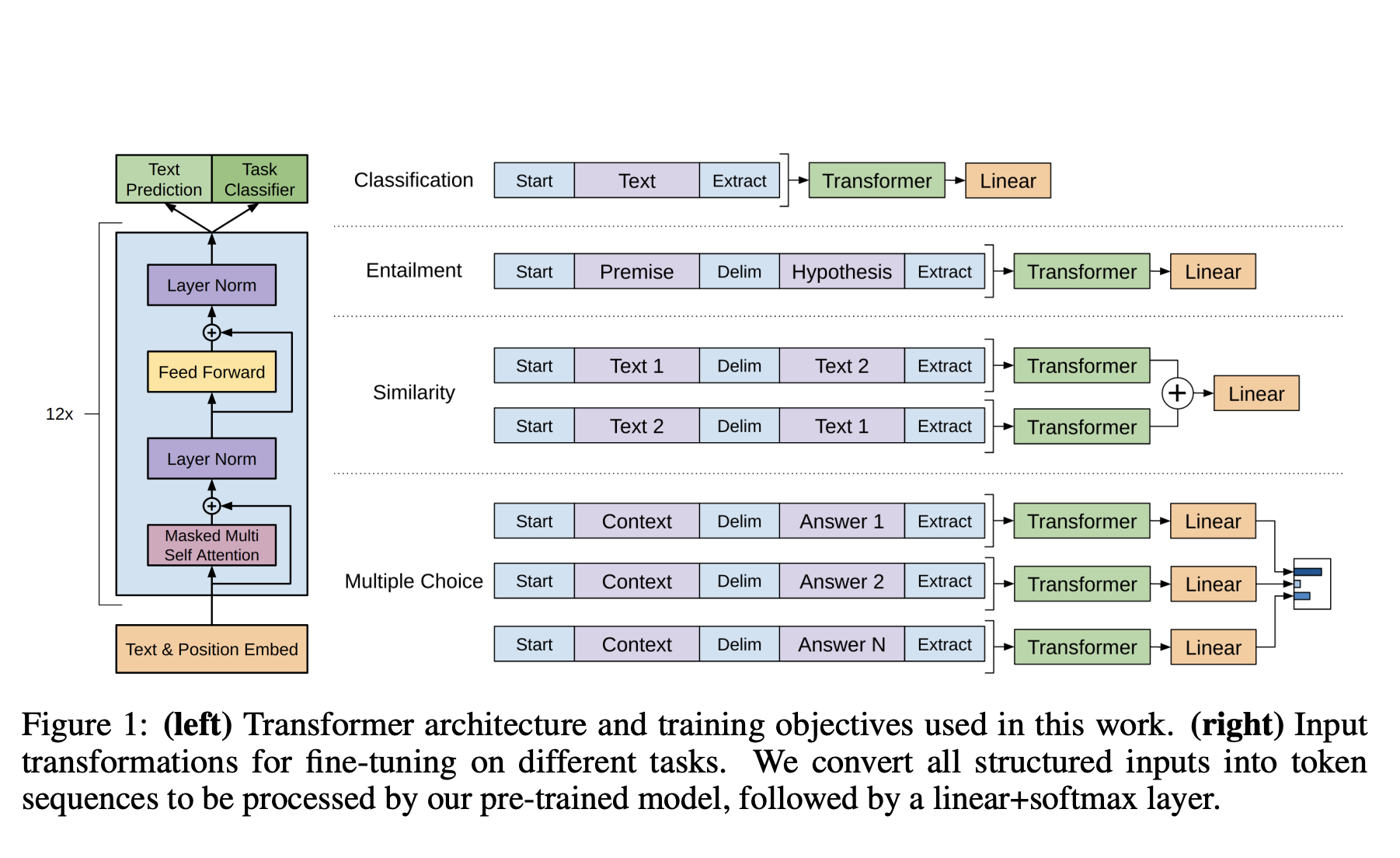
概括下来,GPT-1 的核心是通过在大量未标记文本语料库上对语言模型进行生成式预训练(generative pre-training),然后对每个特定任务进行判别性微调(discriminative fine-tuning),来提高自然语言理解能力。
GPT-2 | 2019
GPT-2 展现出的能力是在特定的数据集上训练时,能够在没有明确监督的情况下学习特定的任务,即 Zero-shot learning。GPT-2 表明在极限情况下,预训练技术能够学习直接执行任务,而不需要监督适应或者修改。
下图表明 GPT-2 在多个任务上进行了实验的结果,表明 GPT-2 只有在具有足够的容量时才能够在许多典型的任务上取得良好的零样本表现。
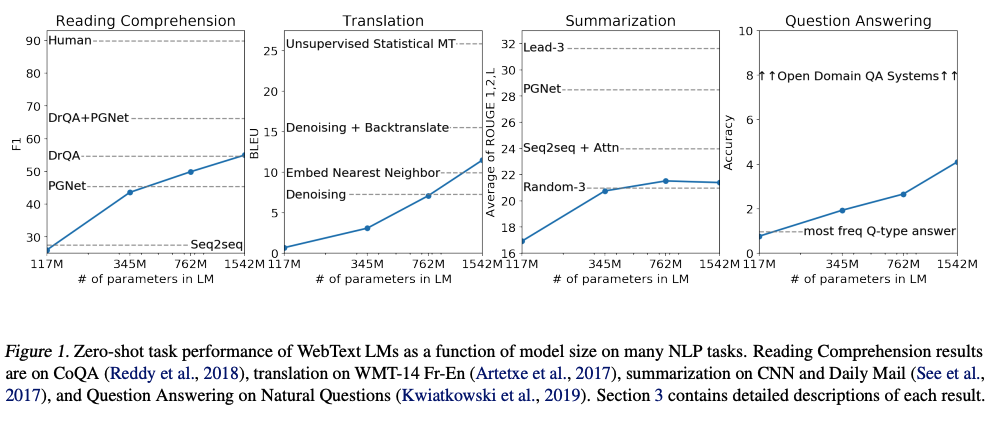
虽然 GPT-2 的零样本表现为很多任务建立了 baseline,但并不清楚 fine-tuning 的上限。于是沿着 GPT-2 的思路,诞生了 GPT-3.
GPT-3 | 2020
GPT-3 便沿着 GPT-2 的思路,思考如何让下游任务更好的适配预训练语言模型。
首先他们在无监督预训练阶段,加入了"in-context learning"。简单讲就是模型在不更新自身参数的情况下,通过在模型输入中代入新任务的描述和少量样本,就能让模型“学习”的新任务的特征。

GPT-3 没有使用 fine-tuning,而是在 in-context learning 阶段尝试了三种设定:Zero-sot,One-shot 以及 Few-shot。Prompt 便是在这个阶段加入的。

其次,他们使用了更多、更高质量的语料,训练出了更大的模型。

GPT-3 一经发布,便引起了学术界产业界爱好者们前沿的广泛讨论, 列举几篇
- 虎嗅的:与 GPT-3 对话:它的回答令人细思极恐
- AI TIME:地表最强的 GPT-3,是在推理,还是胡言乱语?
- 新智元:GPT-3 真是人工智能「核武器」吗?花 1200 万美元训练却没能通过图灵测试
研究者们也在论文中提出了一些关于 GPT-3 的担忧。
- 语言模型的滥用
- 公平性、偏见上的挑战
- 资源消耗巨大
当然,困难是不会打倒开拓者们的。
InstructGPT | 2022
InstructGPT 的核心是如何让 GPT 生成的回答更符合人类的需求。而该模型引入了一种名为 RLHF 的方法来进行微调。结果表明,InstructGPT 模型的输出比 GPT-3 更受欢迎,而且更真实,更少的有毒输出。利用 RLHF 微调,是使语言模型与人类意图保持一致的一个有前途的方向。
概括起来就三个步骤
- 预训练一个语言模型 (LM),并在高质量 prompt 数据集上进行有监督微调
- 聚合对比数据并训练一个奖励模型 (Reward Model,RM)
- 用强化学习 (RL) 方式微调 LM
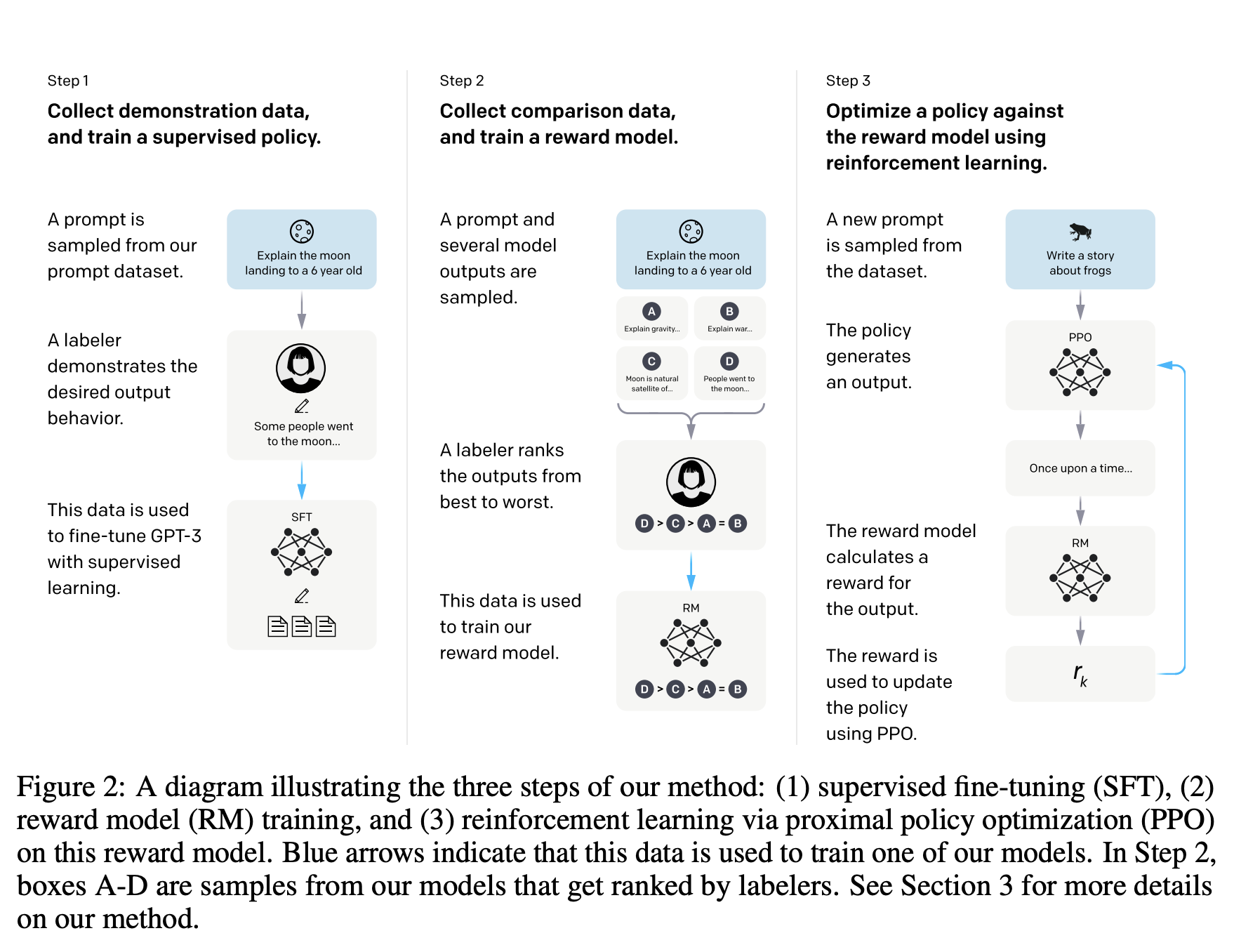
于是,GPT 便朝着人类期望的方向不断的进化了。
ChatGPT | 2022 末
2022 年 11 月 30 日,OpenAI 发布了一个通过由 GPT-3.5 系列 LLM 微调而成的全新对话式 AI 工具 ChatGPT,掀起了人工智能的热潮。
拐点已至 | 2023
-
OpenAI 获得微软投资 100 亿美元
One More Thing
文章开头引用来自于陆奇最新演讲《我的大模型世界观》 ,利用AI总结了以下几点take-away:
- 大模型时代的发展速度非常快,甚至他自己都跟不上
- OpenAI在大模型领域处于领先地位,并且未来有可能比Google更大
- 未来是一个模型无处不在的时代
- 大模型时代对每个人都将产生深远和系统性影响,每个人很快将有副驾驶员
- 陆奇认为,创业公司基本上有三类:数字化技术、满足人类需求和改变世界
如果您还未能将使用ChatGPT等AI作为习惯,我感到非常遗憾。
如果您还没有使用 ChatGPT 的渠道,关注这个公众号👇并打招呼,可以获取使用入口。
- Blog Link: https://neo1989.net/Way2AI/Way2AI-gpt-history/
- Copyright Declaration: 转载请声明出处。