Way2AI · Pandas
TL;DR
Way2AI系列,确保出发去"改变世界"之前,我们已经打下了一个坚实的基础。
本文简单介绍了Pandas这个数据分析处理库的必备知识。
Set up
首先,我们将导入NumPy和Pandas库,并设置随机种子以实现可重复性。
我们还要下载一个数据集。
1 | import numpy as np |
Load Data
我们将在 Titanic 这个数据集上完成学习,这是一个非常常见且丰富的数据集,包含了1912年登上泰坦尼克号的人员相关信息以及他们在远航中幸存与否,非常适合使用Pandas进行探索性数据分析。
让我们将CSV文件中的数据加载到Pandas dataframe中。header=0表示第一行(索引为0)是一个标题行,其中包含了我们数据集中每个列的名称。
1 |
|
输出如下图所示:

解释一下数据的特征列:
- PassengerId: ID
- Survived: 存活指标(0 - died, 1 - survived)
- Pclass: 票的等级
- Name: 旅客的全名
- Sex: 性别
- Age: 年龄
- SibSp: 兄弟姐妹 / 配偶
- Parch: 父母 / 子女
- Ticket: 票号
- Fare: 票价
- Cabin: 房间号
- Embarked: 出发的港口
探索性数据分析 (EDA)
现在我们已经加载了数据,准备开始探索以找到有用的信息。
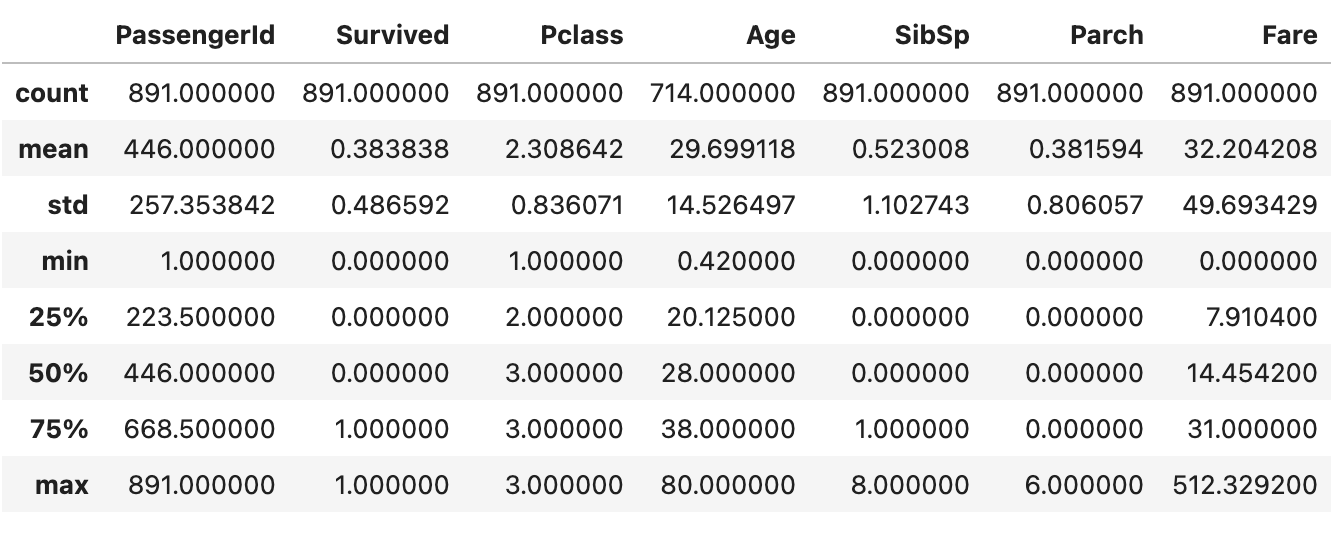
我们可以使用 .describe() 方法提取数值特征的一些标准细节。
1 | # Describe features |
输出如下图所示:
导入matplotlib以提供更直观的数据可视化。
1 | import matplotlib.pyplot as plt |
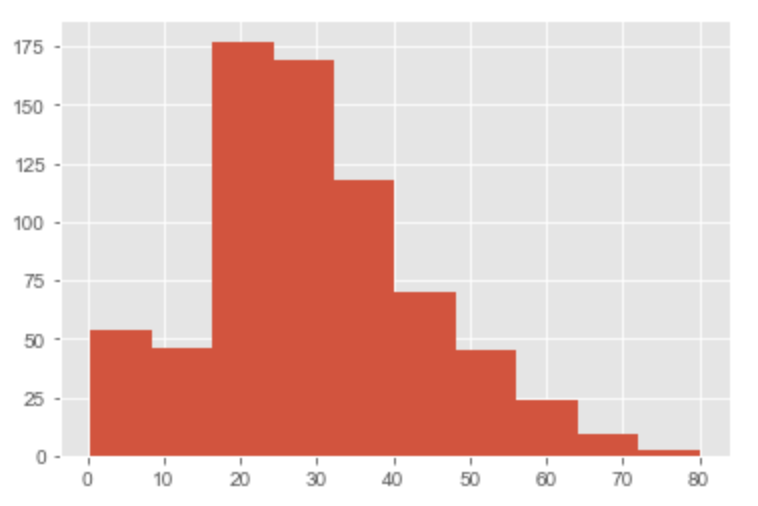
我们还可以使用.hist()函数来查看每个特征的值的直方图。
1 | # Histograms |
使用.unique()函数查看特征值的所有类别。
1 | # Unique values |
Filtering
我们可以按照特征甚至是特定特征中的具体值(或值范围)来过滤数据。
1 | # Selecting data by feature |

Sorting
我们还可以按升序或降序对功能进行排序。
1 | # Sorting |

Grouping
我们还可以针对特定分组获取特征的统计数据。在这里,我们想根据乘客是否幸存来查看连续特征的平均值。
1 | # Grouping |

Indexing
我们可以使用iloc在数据框中获取特定位置的行或列。
1 | # Selecting row 0 |
Preprocessing
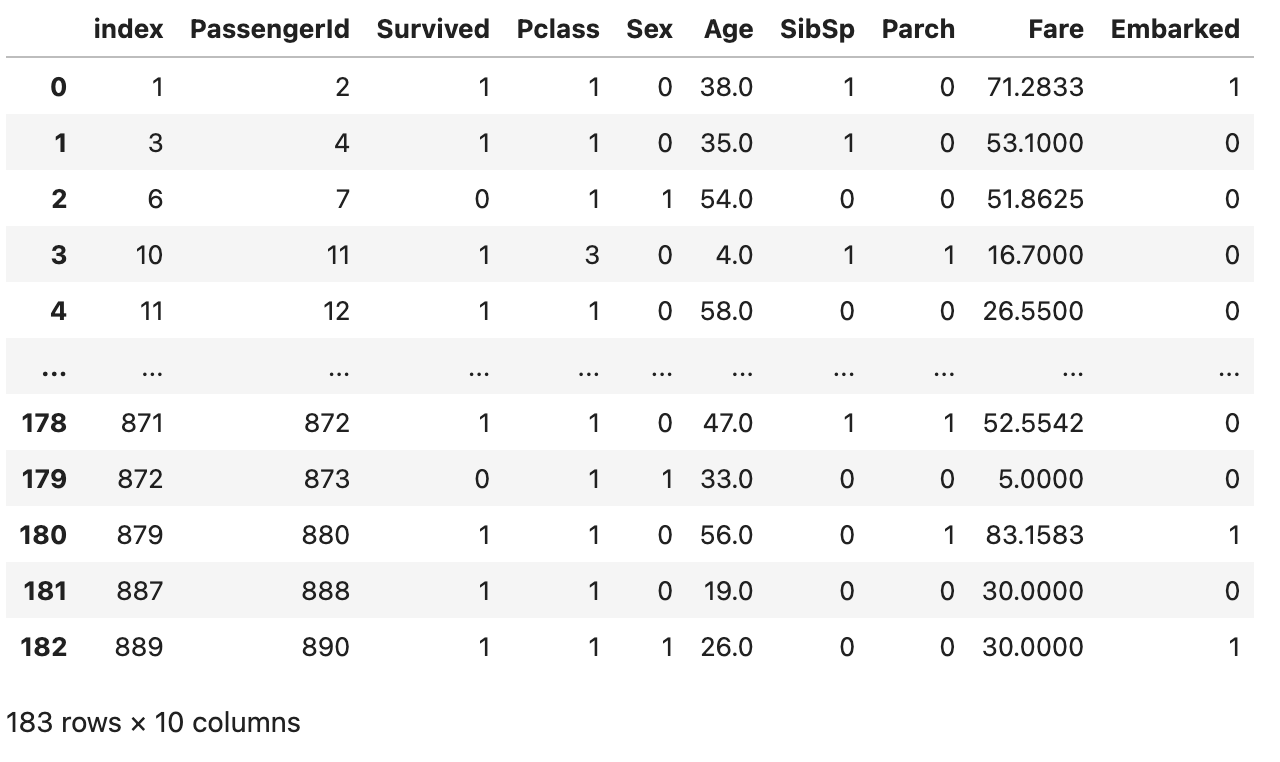
在探索完数据后,我们可以对数据集进行清洗和预处理。
1 | # Rows with at least one NaN value |

1 | # Drop rows with Nan values |
结果如下:
Feature Engineering 特征工程
我们现在要使用特征工程来创建一个名为FamilySize的列。我们将首先定义一个名为get_family_size的函数,该函数将使用父母和兄弟姐妹数量来确定家庭大小。
1 | # Lambda expressions to create new features |
我们就可以使用lambda将该函数应用于每一行(使用每行中兄弟姐妹和父母的数量来确定每行的家庭规模)。
1 | df["FamilySize"] = df[["SibSp", "Parch"]].apply(lambda x: get_family_size(x["SibSp"], x["Parch"]), axis=1) |
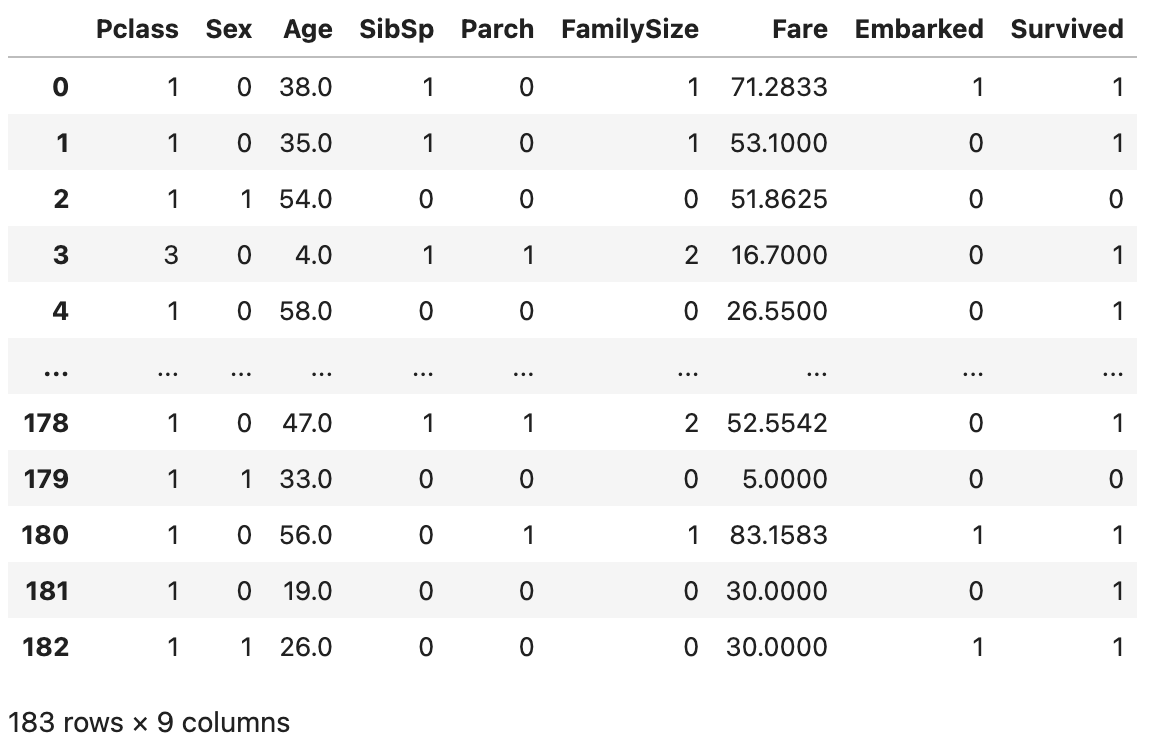
特征工程可以与领域专家合作进行,他们可以指导我们在工程和使用哪些特征。
Save Data
最后,让我们将预处理后的数据保存到一个新的CSV文件中以备后用。
1 | # Saving dataframe to CSV |
Scaling
当处理非常大的数据集时,我们的Pandas DataFrames可能会变得非常庞大,对它们进行操作可能会变得非常缓慢或不可行。这就是分布式工作负载或在更高效硬件上运行的软件包派上用场的地方。
当然,我们可以将它们(Dask-cuDF)结合在一起,在GPU上对dataframe分块进行操作。
Citation
1 | @article{madewithml, |
Ending
到这里,便拥有了Way2AI路上需要的Pandas的必备知识。
但我们不应该止步于此。Pandas官网 上有关于Pandas的全部知识。
- Blog Link: https://neo1989.net/Way2AI/Way2AI-Pandas/
- Copyright Declaration: 转载请声明出处。