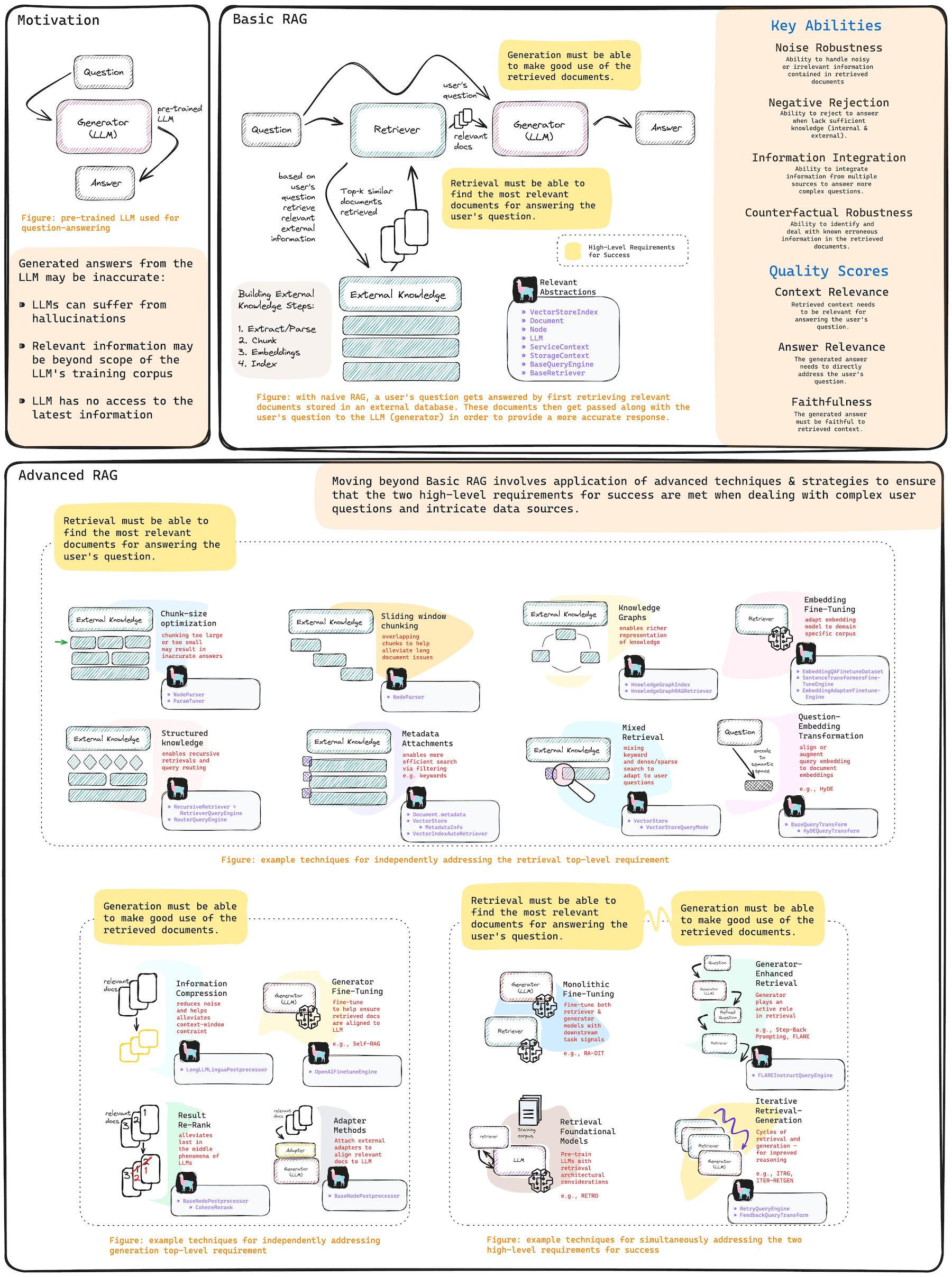
from llama_index import SimpleDirectoryReader, VectorStoreIndex
# load data documents = SimpleDirectoryReader(input_dir="...").load_data()
# build VectorStoreIndex that takes care of chunking documents # and encoding chunks to embeddings for future retrieval index = VectorStoreIndex.from_documents(documents=documents)
# The QueryEngine class is equipped with the generator # and facilitates the retrieval and generation steps query_engine = index.as_query_engine()
# Use your Default RAG response = query_engine.query("A user's query")
from llama_index import ServiceContext from llama_index.param_tuner.base import ParamTuner, RunResult from llama_index.evaluation import SemanticSimilarityEvaluator, BatchEvalRunner
### Recipe ### Perform hyperparameter tuning as in traditional ML via grid-search ### 1. Define an objective function that ranks different parameter combos ### 2. Build ParamTuner object ### 3. Execute hyperparameter tuning with ParamTuner.tune()
from llama_index import SimpleDirectoryReader, VectorStoreIndex from llama_index.node_parser import SentenceSplitter from llama_index.schema import IndexNode
### Recipe ### Build a recursive retriever that retrieves using small chunks ### but passes associated larger chunks to the generation stage
# load data documents = SimpleDirectoryReader( input_file="..." ).load_data()
# define smaller child chunks sub_chunk_sizes = [256, 512] sub_node_parsers = [ SentenceSplitter(chunk_size=c, chunk_overlap=20) for c in sub_chunk_sizes ] all_nodes = [] for base_node in base_nodes; for n in sub_node_parsers: sub_nodes = n.get_nodes_from_documents([base_node]) sub_inodes = [ IndexNode.from_text_node(sn, base_node.node_id) for sn in sub_nodes ] all_nodes.extend(sub_inodes) # also add original node to node original_node = IndexNode.from_text_node(base_node, base_node.node_id) all_nodes.append(original_node)
# define a VectorStoreIndex with all of the nodes vector_index_chunk = VectorStoreIndex( all_nodes, service_context=service_context )
# define a VectorStoreIndex with all of the nodes vector_index_chunk = VectorStoreIndex( all_nodes, service_context=service_context ) vector_retriever_chunk = vector_index_chunk.as_retriever(similarity_top_k=2)
# build RecursiveRetriever all_node_dict = {n.node_id: n for n in all_nodes} retriever_chunk = RecursiveRetriever( "vector", retriever_dict={"vector": vector_retriever_chunk}, node_dict=all_nodes_dict, verbose=True )
# perform inference with advanced RAG (i.e. query engine) response = query_engine_chunk.query( "Can you tell me about the key concepts for safety finetuning" )
from llama_index import SimpleDirectoryReader, VectorStoreIndex from llama_index.query_engine import RetrieverQueryEngine from llama_index.postprocessor import LongLLMLinguaPostprocessor
### Recipe ### Define a Postprocessor object, here LongLLMLinguaPostprocessor ### Build QueryEngine that uses this Postprocessor on retrieved docs
# Define Postprocessor node_postprocessor = LongLLMLinguaPostprocessor( instruction_str="Given the context, please answer the final question", target_token=300, rank_method="longllmlingua", additional_compress_kwargs={ "condition_compare": True, "condition_in_question": "after", "context_budget": "+100", "reorder_context": "sort", }, )
# Define VectorStoreIndex documents = SimpleDirectoryReader(input_dir="...").load_data() index = VectorStoreIndex.from_documents(documents)
import os from llama_index import SimpleDirectoryReader, VectorStoreIndex from llama_index.postprocessor.cohere_rerank import CohereRerank from llama_index.postprocessor import LongLLMLinguaPostprocessor
### Recipe ### Define a Postprocessor object, here CohereRerank ### Build QueryEngine that uses this Postprocessor on retrieved docs
# Build QueryEngine (RAG) using the post processor documents = SimpleDirectoryReader("...").load_data() index = VectorStoreIndex.from_documents(documents=documents) query_engine = index.as_query_engine( similarity_top_k=10, node_postprocessor=[cohere_rerank], )
# Use your advanced RAG response = query_engine.query( "What did Sam Altman do in this essay?" )
from llama_index.llms import OpenAI from llama_index.query_engine import FLAREInstructQueryEngine from llama_index import ( VectorStoreIndex, SimpleDirectoryReader, ServiceContext, )
### Recipe ### Build a FLAREInstructQueryEngine which has the generator LLM play ### a more active role in retrieval by prompting it to elicit retrieval ### instructions on what it needs to answer the user query.
from llama_index.query_engine import RetryQueryEngine from llama_index.evaluation import RelevancyEvaluator
### Recipe ### Build a RetryQueryEngine which performs retrieval-generation cycles ### until it either achieves a passing evaluation or a max number of ### cycles has been reached