Golang小记
- 1. Go的设计哲学
- 2. 使用Go命名惯例对标识符进行命名
- 3. 使用一致的变量的声明形式
- 4. 使用无类型常量简化代码
- 5. 使用iota实现枚举常量
- 6. 尽量定义零值可用的类型
- 7. 使用复合字面值作为初值构造器
- 8. 了解切片实现原理并高效使用
- 9. 了解map实现原理并高效使用
- 10. 了解string实现原理并高效使用
- 11. 理解Go语言的包导入
- 12. 理解Go语言表达式的求值顺序
- 13. 理解Go语言代码块与作用域
- 14. 了解Go语言控制语句惯用法及使用注意事项
- 15. 在init函数中检查包级变量
- 16. 让自己习惯于函数是“一等公民”
- 17. 使用defer让函数更简洁、更健壮
- 18. 理解方法的本质以选择正确的receiver类型
- 19. 方法集合决定接口实现
- 20. 了解变长参数函数的妙用
- 21. 了解接口类型变量的内部表示
- 22. 尽量定义小接口
- 23. 尽量避免使用空接口作为函数参数类型
- 24. 使用接口作为程序水平组合的连接点
- 25. 使用接口提高代码的可测试性
- 26. 优先考虑并发设计
- 27. 了解goroutine的调度原理
- 28. 掌握Go并发模型和常见并发模式
- 29. 了解channel的妙用
- 30. 了解sync包的正确用法
- 31. 使用atomic包实现伸缩性更好的并发读取
- 32. 了解错误处理的4种策略
- 33. 尽量优化反复出现的 if err != nil
- 34. 不要使用panic进行正常的错误处理
- 35. 理解包内测试与包外测试的差别
- 36. 有层次地组织测试代码
- 37. 优先编写表驱动的测试
- 38. 使用testdata管理测试依赖的外部数据文件
- 39. 正确运用fake、stub和mock等辅助单元测试
- 40. 使用模糊测试让潜在bug无处遁形
- 41. 为被测对象建立性能基准
- 42. 使用pprof对程序进行性能剖析
- 43. 使用expvar输出度量数据,辅助定位性能瓶颈点
- 44. 使用Delve调试Go代码
- 45. Reference
Go的设计哲学
Go在语言层面的简单让Go收货了不逊于C++/Java等的表现力的同时,还获得了更好的可读性、更高的开发效率等在软件工程领域更为重要的元素。
“高内聚、低耦合”。Go崇尚通过组合的方式将正交的语法元素组这在一起来形成应用程序骨架,接口就是在这一哲学下诞生的语言精华。
Go语言提供了内置于语言中的简单并发原语——go(goroutine)、channel和select,大幅降低了开发人员在云计算多核时代编写大规模并发网络服务程序时的心智负担。
Go工具链:
构建和运行:go build / go run
依赖包查看与获取:go list / go get / go mod xx
编辑辅助格式化:go fmt / gofmt
文档查看:go doc / godoc
单元测试/基准测试/测试覆盖率:go test
代码静态分析:go vet
性能剖析与跟踪结果查看:go tool pprof / go tool trace
升级到新Go版本API的辅助工具:go tool fix
报告Go语言bug:go bug
使用Go命名惯例对标识符进行命名
Go语言追求简单一致且利用上下文辅助名字信息传达的命名惯例。
使用一致的变量的声明形式
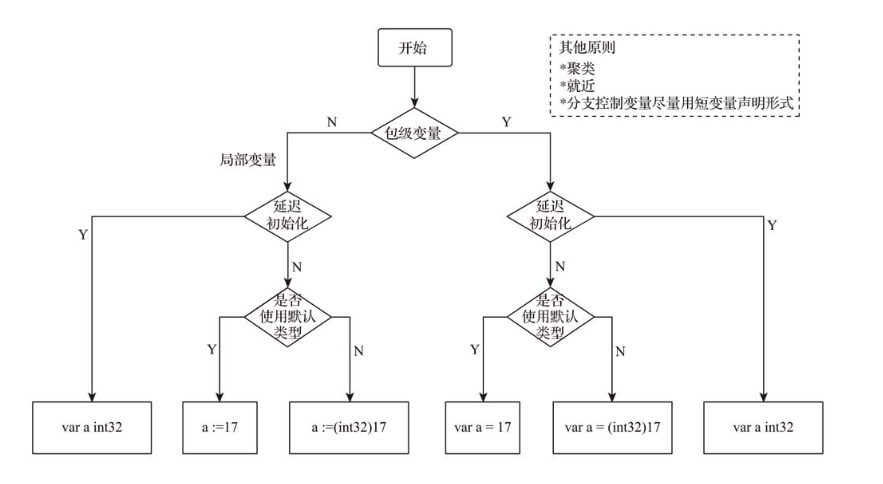
如图示,要想做好代码中变量声明的一致性,需要明确要声明的变量是包级变量还是局部变量、是否要延迟初始化、是否接受默认类型、是否为分支控制变量,并结合聚类和就近原则。
使用无类型常量简化代码
所有常量表达式的求值计算都可以在编译期而不是在运行期完成,这样既可以减少运行时的工作,也能方便编译器进行编译优化。当操作数是常量时,在编译时也能发现一些运行时的错误,例如整数除零、字符串索引越界等。
无类型常量是Go语言推荐的实践,它拥有和字面值一样的零或特性,可以直接用于更多的表达式而不需要进行显示类型转换,从而简化了代码编写。此外,按照Go官方语言规范的描述,数值型无类型常量可以提供比基础类型更高精度的算术运算,至少有256bit的运算精度。
使用iota实现枚举常量
尽量定义零值可用的类型
Go语言零值可用的理念给内置类型、标准库的使用者带来很多遍历。不过Go并非所有类型都零值可用的,并且零值可用也有一定的限制,比如:
在append场景下,零值可用的切片类型不能通过下标形式操作数据:
1 | var s []int |
另外,像map这样的原生类型也没有提供对零值可用的支持:
1 | var m map[string]int |
另外零值可用的类型要注意尽量避免值复制:
1 | var mu sync.Mutex |
我们可以通过指针方式传递类似Mutex这样的类型:
1 | var mu sync.Mutex |
保持与Go一致的理念,给自定义的类型一个合理的零值,并尽量保持自定义类型的零值可用,这样我们的Go代码会更加复合Go语言的惯用法。
使用复合字面值作为初值构造器
对于零值不适用的场景,我们要为变量赋予一定的初值。对于复合类型,我们应该首选Go提供的复合字面值作为初值构造器。对于不同复合类型,我们要记住下面几点:
- 使用field: value 形式的复合字面值为结构体类型的变量赋初值。
- 在为稀疏元素赋值或让编译器推导数组大小的时候,多使用index: value的形式为数组/切片类型变量赋初值。
- 使用key: value形式的复合字面值为map类型的变量赋初值。(Go 1.5版本后,复合字面值中的key和value类型均可以省略不写。)
了解切片实现原理并高效使用
切片是数组的描述符,在大多数场合替代了数组,并减少了数组指针作为函数参数的使用。
append在切片上的运用让切片类型部分支持了“零值可用”的理念,并且append对切片的动态扩容将Gopher从手工管理底层存储的工作中解放出来。
在可以预估初元素容量的前提下,使用cap参数创建切片可以提升append的平均操作性能,减少或消除因动态扩容带来的性能损耗。
了解map实现原理并高效使用
- 不要依赖map的元素遍历顺序
- map不是线程安全的,不支持并发写
- 不要尝试获取map中元素(value)的地址
- 尽量使用cap参数创建map,以提升map平均访问性能,减少频繁扩容带来的不必要损耗
了解string实现原理并高效使用
Go语言内置了string类型,统一了对字符串的抽象,并且为string类型提供提供了强大的内置操作支持,包括基于+/+=的字符串连接操作,基于==、!=、>、<等的比较操作,O(1)复杂度的长度获取操作,对非ASCII字符提供原生支持,对string类型与slice类型的相互转换提供优化等。
此外,Go语言还在标准库中提供了strings和strconv包,可以辅助Gopher对string类型数据进行更多高级操作。
理解Go语言的包导入
- Go编译器在编译过程种必然要使用的是编译单元(一个包)所依赖的包的源码
- Go源码文件头部的包导入语句中import后面的部分是一个路径,路径的最后一个分段是目录名,而不是包名。
- Go编译器的包源码搜索路径由基本搜索路径和包导入路径组成,两者结合在一起后,编译器便可确定一个包的所有依赖包的源码路径的集合,这个集合构成了Go编译器的源码搜索路径空间。
- 同一源码文件的依赖包在同一源码搜索路径空间下的包名冲突问题可以由显示指定包名的方式解决。
理解Go语言表达式的求值顺序
- 包级别变量声明语句中的表达式求值顺序由变量的声明顺序和初始化依赖关系决定,并且包级变量表达式求值顺序优先级最高。
- 表达式操作数中的函数、方法及channel操作按普通求值顺序,即从左到右的次序进行求值。
- 赋值语句求值分为两个阶段:先按照普通求值规则对等号左边的下标表达式、指针解引用表达式和等号右边的表达式中的操作数进行求值,然后按从左到右的顺序对变量进行赋值。
- 重点关注switch-case和select-case语句中的表达式“惰性求值”规则。
理解Go语言代码块与作用域
了解Go语言控制语句惯用法及使用注意事项
- 使用if语句时遵循“快乐路径”原则
- 小心for range的循环变量重用,明确真实参与循环的是range表达式的副本
- 明确break和continue执行后的真实“目的地”
- 使用fallthrough关键字前,考虑能否用简洁、清晰的case表达式列表替代
1 | /* |
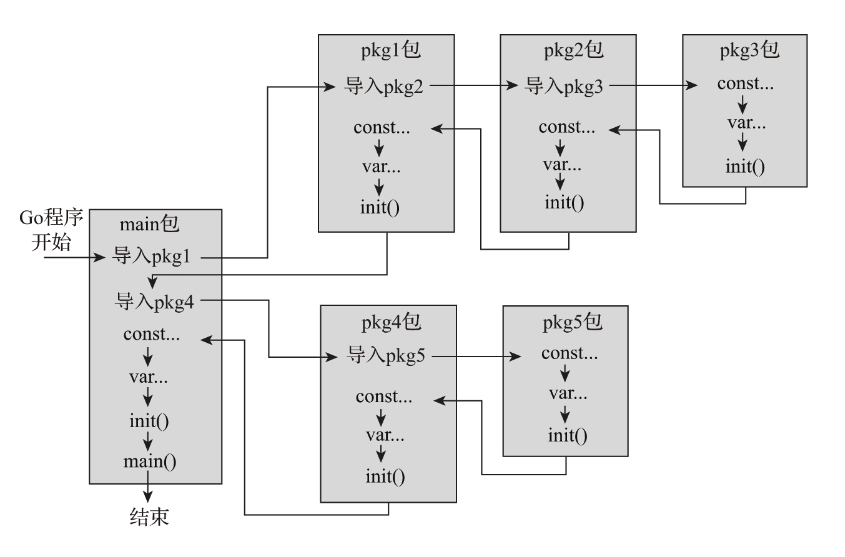
在init函数中检查包级变量
- init函数有几个特点:运行时调用、顺序、仅执行一次
- init函数是包出厂前的唯一“质检员”
- 记住Go程序的初始化顺序

让自己习惯于函数是“一等公民”
- Go函数可以像变量值那样被赋值给变量、作为参数传递、作为返回值返回和在函数内部创建等
- 函数可以像变量那样被显示类型转换
- 基于函数特质,了解Go中的几种有用的函数式编程风格,如柯里化、函子等
- 不要为了复合特定风格而滥用函数特质
使用defer让函数更简洁、更健壮
- 理解defer的运作机制,即deferred函数注册与调度执行
- 了解defer的常见用法
- 了解关于defer使用的几个关键问题,避免入“坑”
理解方法的本质以选择正确的receiver类型
- Go方法的本质:一个以方法所绑定类型实例为第一个参数的普通函数。。
- Go语法糖使得我们在通过类型实例调用类型方法时无须考虑实例类型与receiver参数类型是否一致,编译器会为我们做自动转换。
- 在选择receiver参数类型时要看是否要对类型实例进行修改。如有修改需求,则选择
*T;如无修改需求,T类型receiver传值的性能损耗也是考量因素之一。
方法集合决定接口实现
- 方法集合是类型与接口间隐式关系的纽带,只有当类型的方法集合是某接口类型的超集时,我们才说类型实现了某接口
- 类型T的方法集合是以T为receiver类型的所有方法的集合,类型
*T的方法集合是以*T为receiver类型的所有方法的集合与类型T的方法集合的并集 - 了解类型嵌入对接口类型和自定义结构体类型的方法集合的影响
- 基于接口类型创建的defined类型与原类型具有相同的方法集合,而基于自定义非接口类型创建的defined类型的方法集合为空
- 类型别名与原类型拥有完全相同的方法集合
了解变长参数函数的妙用
- 了解变长参数函数的特点和约束
- 变长参数可以在有限情况下模拟函数重载、可选参数和默认参数,但要谨慎使用,不要造成混淆
- 利用变长参数函数实现功能选项模式
了解接口类型变量的内部表示
- 接口类型变量在运行时表示为eface和iface,eface用于表示空接口类型变量,iface用于表示非空接口类型变量
- 当且仅当两个接口类型变量的类型信息(eface.__type / iface.tab.__type)相同,同数据指针(eface.data / iface.data)所指数据相同时,两个接口类型才是相等的
- 通过println可以输出接口类型变量的两部分指针变量的值
- 可通过复制runtime包eface和iface相关类型源码,自定义输出eface/iface详尽信息的函数
- 接口类型变量的装箱操作由Go编译器和运行时共同完成
尽量定义小接口
- 接口是将对象的行为进行抽象而形成的契约
- Go青睐定义小接口,即方法数量为1~3个、通常为1个的接口 (接口方法数量统计工具)
- 小接口抽象程度高,被接纳度高,易于实现和测试,易于复用组合
- 先抽象出接口,再拆分为小接口,另外接口的契约职责应尽可能保持单一
尽量避免使用空接口作为函数参数类型
使用接口作为程序水平组合的连接点
- 深入理解Go的组合设计哲学
- 垂直组合可实现方法实现和接口定义的重用
- 掌握使用接口作为程序水平组合的连接点的几种形式
使用接口提高代码的可测试性
适当抽取接口,让接口成为好代码与单元测试之间的桥梁是Go语言的一种最佳实践。
优先考虑并发设计
并发在程序的设计和实现阶段,并行在程序的执行阶段。
了解goroutine的调度原理
- 了解goroutine调度器要解决的主要问题
- 了解gorutine调度器的调度模型演进
- 掌握goroutine调度器当前G-P-M调度模型的运行原理
- 掌握gorutine调度器状态查看方法
- 学习goroutine调度实例分析方法
掌握Go并发模型和常见并发模式
- 了解基于CSP的并发模型与传统基于共享内存的并发模型的区别
- 了解Go为实现CSP模型而提供的并发原语及功能
- 掌握常见的并发模型,包括创建模式、多种退出模式、管道模式、超时和取消模式等
了解channel的妙用
- 了解Go并发原语channel和select的基本语义
- 掌握无缓冲channel在信息传递、替代锁同步场景下的应用模式
- 掌握带缓冲channel在消息队列、计数信号量场景下的应用模式,了解在特定场景下利用len函数侦测带缓冲channel的状态
- 了解nil channel在特定场景下的用途
- 掌握select与channel结合使用的一些惯用法及注意事项
了解sync包的正确用法
- 明确sync包中原语应用的适用场景
- sync包内定义的结构体或包含这些类型的结构体在首次使用后禁止复制
- 明确sync.RWMutex的使用场景
- 掌握条件变量的应用场景和使用方法
- 实现单利模式时优先考虑sync.Once
- 了解sync.Pool的优点,使用中可能遇到的问题及解决方法
使用atomic包实现伸缩性更好的并发读取
随着并发量提升,使用atomic实现的共享变量的并发读写性能表现更为稳定,尤其是原子读操作,这让atomic与sync包中的原语比起来表现出更好的伸缩性和更高的性能。
atomic包更适合一些对性能十分敏感、并发量较大且读多写少的场合。
但atomic原子操作可用来同步的范围有较大限制,仅是一个整型变量或自定义类型变量。如果要对一个复杂的临界区数据进行同步,那么首选依旧是sync包中的原语。
了解错误处理的4种策略
- 尽量使用透明错误处理策略降低错误处理方与错误值构造方之间的耦合
- 如果可以通过错误值类型的特征进行错误检视,那么尽量使用错误行为特征检视策略
- 在上述两种策略无法实施的情况下,再用“哨兵”策略和错误值类型检视策略
- 在Go1.13及后续版本中,尽量用errors.Is和errors.As方法替换原先的错误检视比较语句
尽量优化反复出现的 if err != nil
- 使用显示错误结果和显示的错误检查是Go语言成功的重要因素,也是
if err != nil反复出现的根本原因 - 了解关于改善Go错误处理的两种观点
- 了解减少甚至消除
if err != nil代码片段的两个优化方向,即改善视觉呈现与降低复杂度 - 掌握错误处理代码优化的四种常见方法,并根据所处场景与约束灵活使用
不要使用panic进行正常的错误处理
- 深入理解不要使用panic进行正常错误处理的原因
- Go标准库中panic的常见使用场景
- 理解程序发生panic时输出的栈帧信息有助于快速定位bug,找出“元凶”
理解包内测试与包外测试的差别
有层次地组织测试代码
优先编写表驱动的测试
使用testdata管理测试依赖的外部数据文件
正确运用fake、stub和mock等辅助单元测试
使用模糊测试让潜在bug无处遁形
为被测对象建立性能基准
使用pprof对程序进行性能剖析
使用expvar输出度量数据,辅助定位性能瓶颈点
使用Delve调试Go代码
Reference
- Blog Link: https://neo1989.net/Notes/NOTE-key-points-for-mastering-golang/
- Copyright Declaration: 转载请声明出处。