幸会 01
《幸会系列》 仅记录本人的本次参与创业的经历,所有与产品相关的介绍和观点仅代表本人理解和看法。
具体产品信息和相关解释应以官方发布为准。
采集
背景
- 需要一些初始数据供开发测试
- 需要书影数据,辅助内容生成
架构
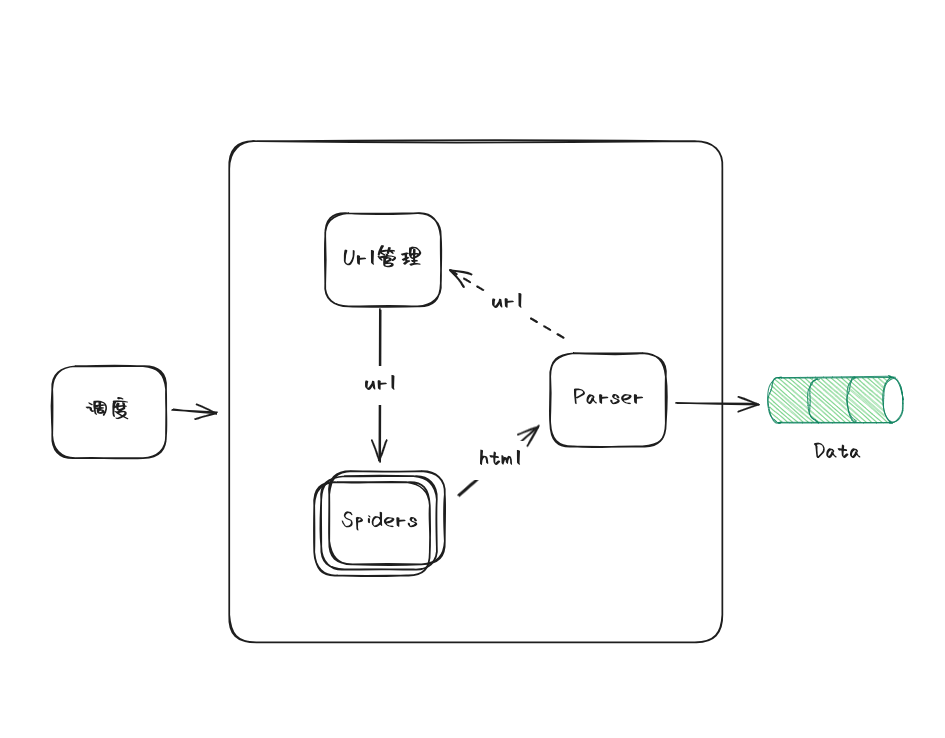
考虑最简单直接的实现。
- URL管理:维护需要爬取的url/params, 通过不通的redis key 区分不通的任务。
- Spider: 监听对应的redis key,执行爬取动作
- Parser: 解析spider拿到的html,保存解析后的数据,补充递归爬取的url(option)
- 调度器:包含url/params初始化、spider的启动、暂定、更新等
流程
Ansible管理多节点,发布并启动Spiders。
管理端初始化url/params,写入redis cluster中的zset(带权重)。
Spider 从 zset 中拿到url/params,执行采集。
采集完成执行解析,解析完成持久化保存数据,并按需写入待采url或params。
注意点
- url/params 需防重复,考虑bloomfilter。
- spider的采集频率
- Blog Link: https://neo1989.net/Jotting/JOTTING-xinghui-01/
- Copyright Declaration: 转载请声明出处。