A Demo of the CNN LSTM
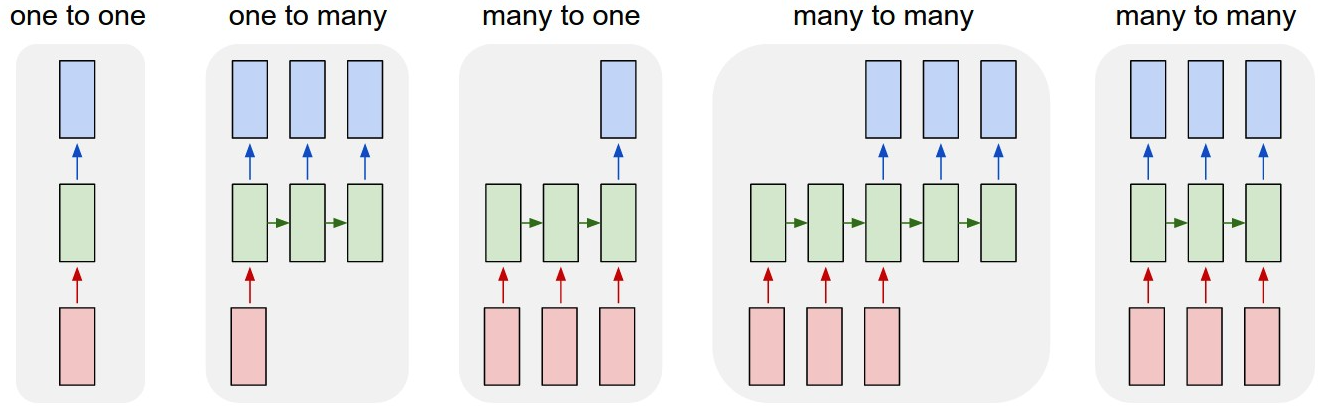
The moving square video prediction problem is contrived to demonstrate the CNN LSTM. The problem involves the generation of a sequence of frames. In each image a line is drawn from left to right or right to left. Each frame shows the extension of the line by one pixel. The task is for the model to classify whether the line moved left or right in the sequence of frames.Technically, the problem is a sequence classification problem framed with a many-to-one prediction model.
"Moving Square Video Prediction"是《Long Short-Term Memory Networks With Python》 这本书里的一个示例。我在这里做了一下扩展,将其变成一个多分类问题。
The Problem
问题定义为一个帧序列,从边缘开始每多一帧就增加一个像素点,以展示朝某个方向延伸的一条线(从上到下,从下到上,从左到右,从右到左)。
模型的任务就是预测这条线是如何运动的。
很明显,这就是一个many-to-one的分类任务。输入帧序列,输出单个标签(图片来源)。
1 | # 代码示例 |

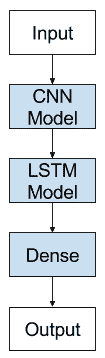
CNN LSTM
使用CNN层对输入数据进行特征提取, 使用LSTM来做序列预测。
这种架构还被用于语音识别和自然语言处理问题,其中CNN被用作音频和文本输入数据上的特征提取器,以供LSTM使用。
此架构适用于以下问题:
- 在其输入中具有空间结构,例如 2D 结构或图像中的像素或句子,段落或文档中的单词的一维结构。
- 在其输入中具有时间结构,诸如视频中的图像的顺序或文本中的单词,或者需要生成具有时间结构的输出,诸如文本描述中的单词。
generate_examples
1 | from sklearn.preprocessing import LabelEncoder, OneHotEncoder |
CNN Model
The Conv2D will interpret snapshots of the image (e.g. small squares) and the pooling layers will consolidate or abstract the interpretation.
We will define a Conv2D as an input layer with 2 filters and a 2 × 2 kernel to pass across the input images. The use of 2 filters was found with some experimentation and it is convention to use small kernel sizes. The Conv2D will output 2 49 × 49 pixel impressions of the input.
Convolutional layers are often immediately followed by a pooling layer. Here we use a MaxPooling2D pooling layer with a pool size of 2 × 2, which will in effect halve the size of each filter output from the previous layer, in turn outputting two 24 × 24 maps.
The pooling layer is followed by a Flatten layer to transform the [24,24,2] 3D output from the MaxPooling2D layer into a one-dimensional 1,152 element vector…
We want to apply the CNN model to each input image and pass on the output of each input image to the LSTM as a single time step.
We can achieve this by wrapping the entire CNN input model (one layer or more) in a TimeDistributed layer.
Next, we can define the LSTM elements of the model. We will use a single LSTM layer with 50 memory cells, configured after a little trial and error. The use of a TimeDistributed wrapper around the whole CNN model means that the LSTM will see 50 time steps, with each time step presenting a 1,152 element vector as input.
1 |
|

fit and evaluate the model
1 | # fit model |

prediction
1 | # prediction on new data |

Further Reading
- Keras API.
- Long-term Recurrent Convolutional Networks for Visual Recognition and Description, 2015.
- Show and Tell: A Neural Image Caption Generator, 2015.
- Convolutional, Long Short-Term Memory, fully connected Deep Neural Networks, 2015.
- Character-Aware Neural Language Models, 2015.
- Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting, 2015.
- Blog Link: https://neo1989.net/HandMades/HANDMADE-CNN-LSTM-try/
- Copyright Declaration: 转载请声明出处。