NLP的神经网络简史
TL;DR
本文主要内容源于NLP神经网络发展史及《A Review of the Neural History of Natural Language Processing》,仅供学习探讨,如有错误均是本人的,与他人无关。
2000 - Neural Language Models
语言建模的任务是在给定前面的词的情况下预测文本中的下一个词。这可能是最简单的语言处理任务,并且有具体的实际应用,比如智能输入法和电子邮件回复建议。语言建模有着丰富的历史,经典的方法是基于n-gram的,并采用平滑处理来解决未见n-grams的问题。
第一个神经网络语言模型 前馈神经网络 首次于2000年在文章《A Neural Probabilistic Language Model》中被提出,并收录于NIPS 2000。
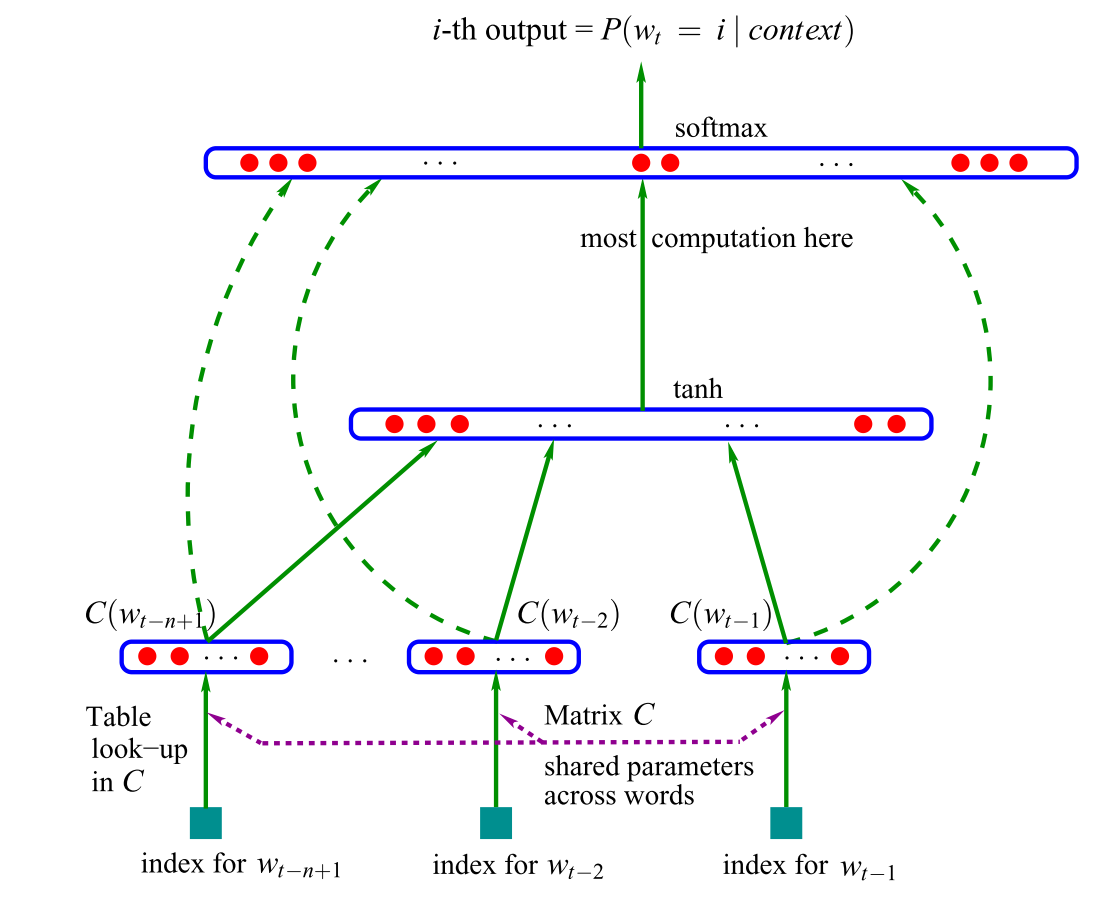
该神经网络语言模型的主要构成如下:
- 输入层:输入通过查询表C得到的前n个词的向量表示。也就是如今大家熟知的词嵌入。
- 隐藏层:将n个词嵌入连接起来,作为隐藏层的输入。以进一步学习词之间的表示。
- 输出层:隐藏层的输出被提供给softmax以输出概率。
该模型的主要novelty在于引入了词嵌入,这比简单的one-hot编码能提供更丰富的词义信息。这些词嵌入可以体现出词与词之间的关系,从而捕捉到更复杂的上下文关系。
模型通过最大似然估计来训练整个网络,找到最优的词嵌入和网络参数,使得模型可以更好地预测下一个词。
关于该模型的更多内容,参考这篇博文。
2008 - Multi-task learning
多任务学习,是一种通过在多个任务上训练模型来共享参数的一般方法。在神经网络中,多任务学习可以通过共享不同层的权重来简单实现。
多任务学习鼓励模型学习对许多任务都有用的表征。这对于学习通用的底层表征,聚焦模型的注意力或在训练数据有限的设置中特别有用。
多任务学习于2008年在文章《A Unified Architecture for Natural Language Processing》中首次被应用于NLP神经网络。在他们的模型中,使用共享的lookup tables(词嵌入矩阵)实现多任务学习。如下图所示
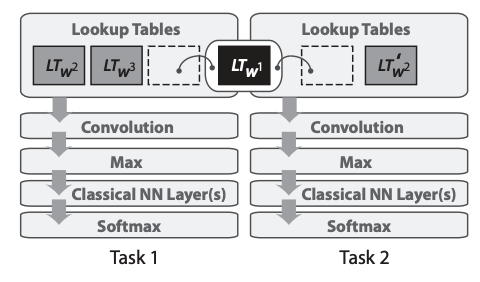
共享词嵌入使得模型能够协作并分享词嵌入矩阵中的底层信息,这通常构成了模型中最大数量的参数。该论文不仅使用了多任务学习,而且还推动了预训练词嵌入和使用卷积神经网络(CNNs)处理文本等思想,这些思想后来来才被广泛采用。而且这篇论文获得了the test-of-time award at ICML 2018。
2013 - Word embeddings
文本的向量表示,在自然语言处理中有着悠久的历史。早在2001年,我们就已经看到了单词的密集向量表示或词嵌入。Mikolov等人于2013年提出的主要创新是通过去除隐藏层并近似目标来使这些单词嵌入的训练更加高效。虽然这些变化在性质上很简单,但它们与高效的word2vec实现一起,使得大规模训练单词嵌入成为可能。
Word2vec有两种不同的模型,如下图所示:连续词袋模型(CBOW)和Skip-gram模型。它们的目标不同:一个是基于周围单词预测中心单词,而另一个则相反。
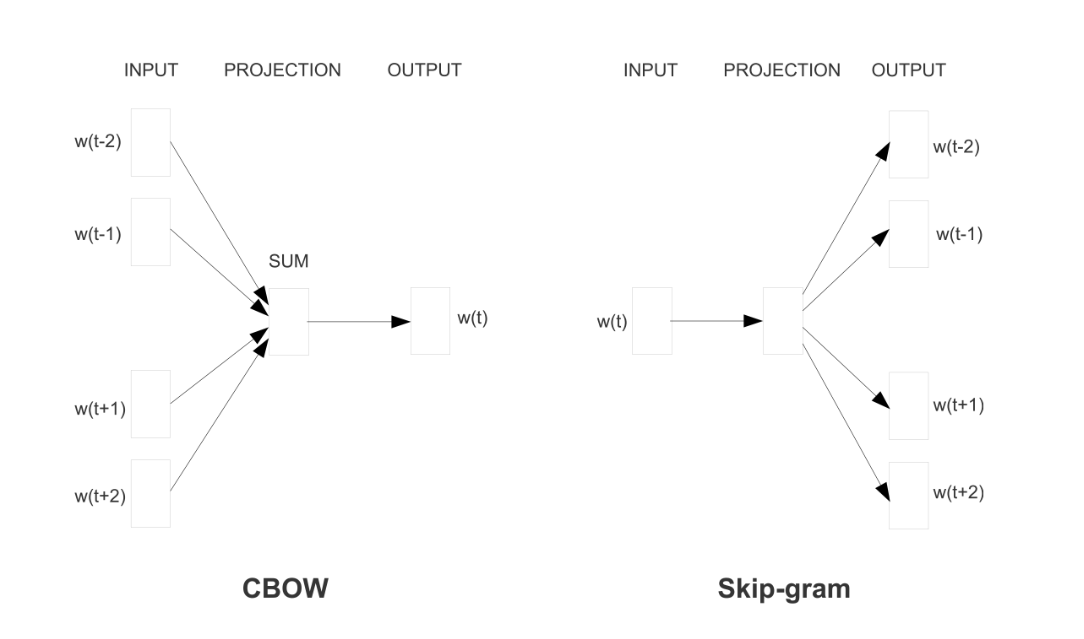
虽然这些嵌入在概念上与使用前馈神经网络学习的嵌入没有区别,但是在大型语料库上进行训练使它们能够捕捉到单词之间的某些关系,例如性别、动词时态和国家-首都关系,如下图所示。
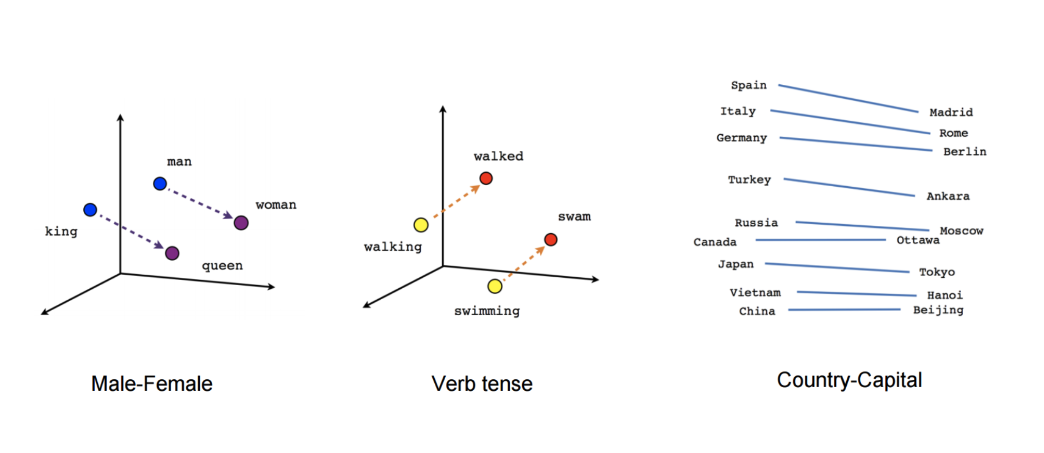
这些关系及其背后的含义引发了对词嵌入的初步兴趣,许多研究探讨了这些线性关系的起源。虽然word2vec捕获的关系具有直观和近乎神奇的特质,但后来的研究表明,word2vec本身并没有什么特别之处:词嵌入也可以通过矩阵分解进行学习,并且经过适当调整,像SVD和LSA这样的经典矩阵分解方法可以实现类似的结果。
2013 - Neural networks for NLP
2013年和2014年是神经网络模型开始在自然语言处理中得到应用的时间。三种主要类型的神经网络变得最为广泛使用:循环神经网络、卷积神经网络和递归神经网络。
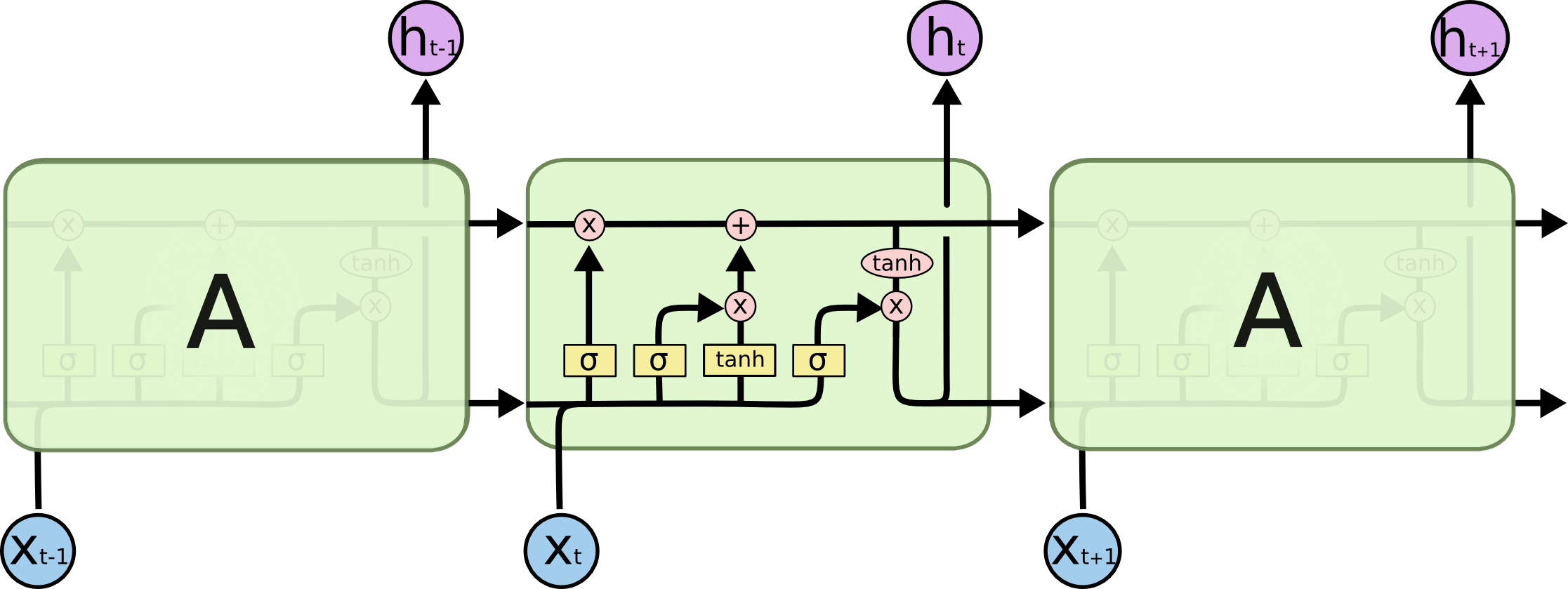
循环神经网络(RNNs)是处理自然语言处理中普遍存在的动态输入序列的明显选择。但传统的Vanilla RNNs(Elman, 1990) 很快被经典的长短期记忆网络(LSTM)(Hochreiter&Schmidhuber, 1997)所取代,后者对于梯度消失和爆炸问题更具鲁棒性。
LSTM单元如下图所示,而一个bidirectional LSTM(Graves et al., 2013)通常用于处理左右两侧的上下文。
随着卷积神经网络(CNNs)在计算机视觉中的广泛应用,它们也开始被应用于语言领域(Kalchbrenner et al., 2014)。文本卷积神经网络仅在两个维度上运行,并且滤波器只需要沿时间维度移动。下图显示了NLP中使用的典型CNN。
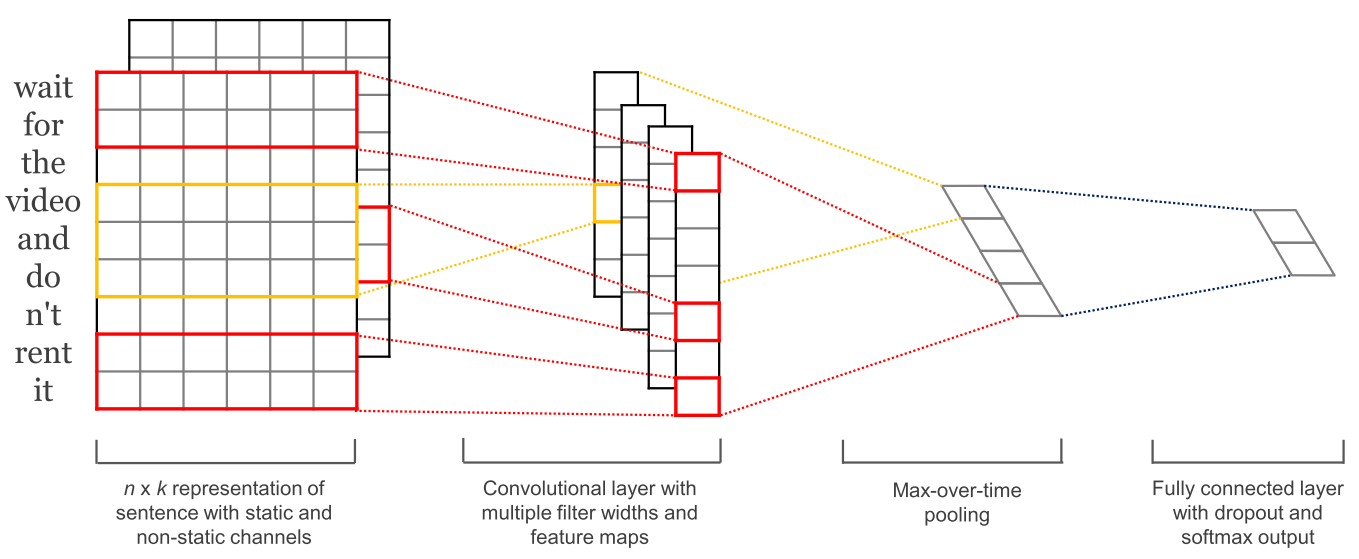
卷积神经网络的一个优点是它们比循环神经网络更易于并行化,因为每个时间步的状态仅取决于局部上下文(通过卷积操作),而不像RNNs中那样依赖所有过去状态。可以使用扩张卷积来扩展具有更广泛感受野的CNNs以捕获更广泛的上下文(Kalchbrenner et al., 2016)。CNNs和LSTMs也可以组合和堆叠,并且可以使用卷积来加速LSTM。
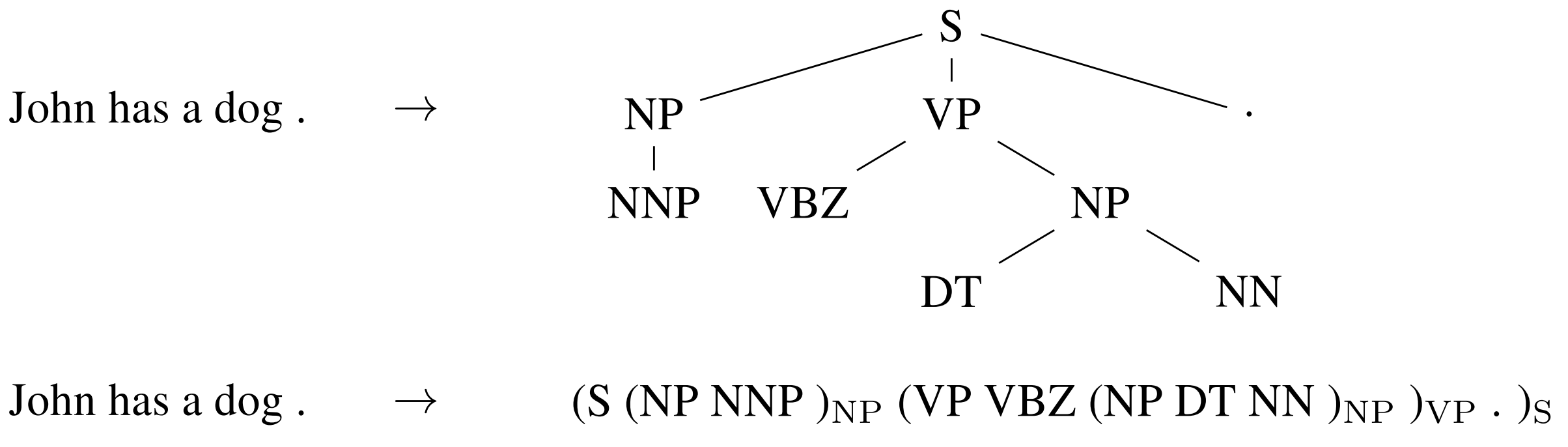
RNNs和CNNs都将语言视为序列。然而,从语言学的角度来看,语言本质上是分层的:单词组成更高级别的短语和从句,这些短语和从句可以根据一组生成规则进行递归组合。在语言学启发下,将句子视为树而不是序列的想法引出了递归神经网络,如下图所示。
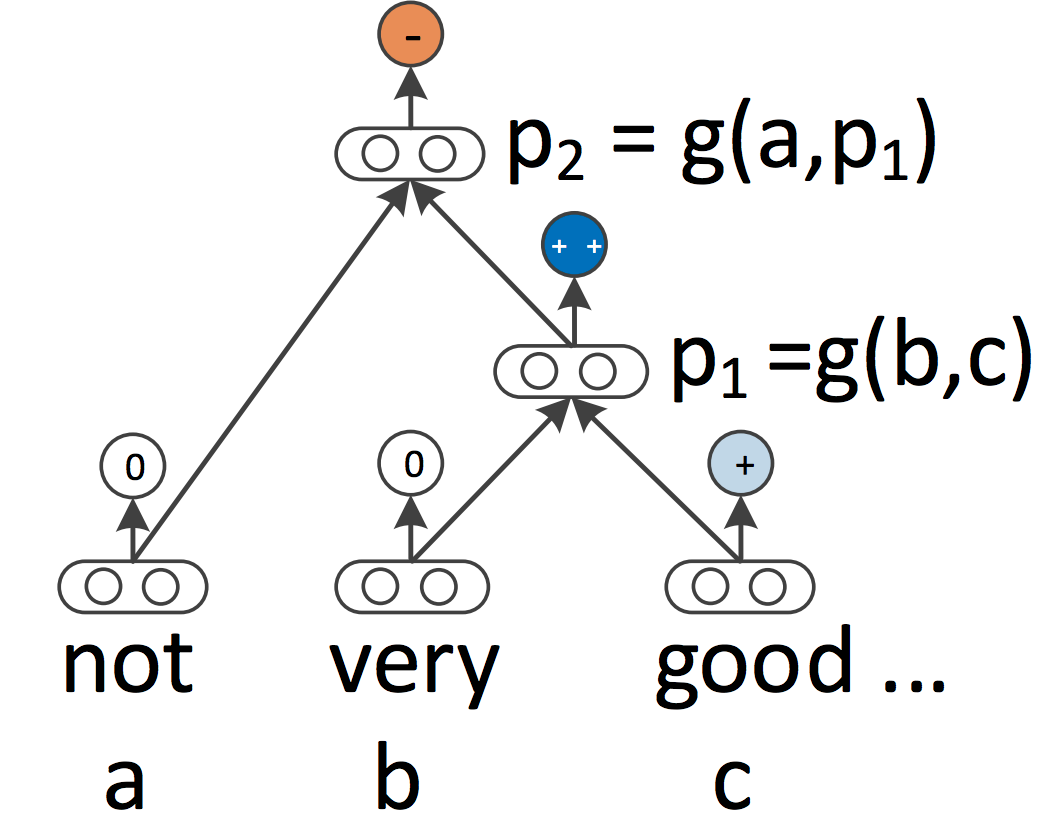
递归神经网络从底部向上构建序列的表示,与RNNs相比,后者是从左到右或从右到左处理句子。在树的每个节点处,通过组合子节点的表示来计算新的表示。由于树也可以被视为对RNNs施加不同的处理顺序,因此LSTMs自然而然地扩展到了树结构。
于是,不只是循环神经网络和长短时记忆网络可以扩展以处理分层结构,词嵌入亦可以基于局部上下文或语法上下文进行学习(Levy&Goldberg, 2014), 语言模型可以根据句法堆栈生成单词(Dyer et al., 2016), 而且图卷积神经网络可以在树上操作(Bastings et al., 2017)。
2014 - Seq2Seq models
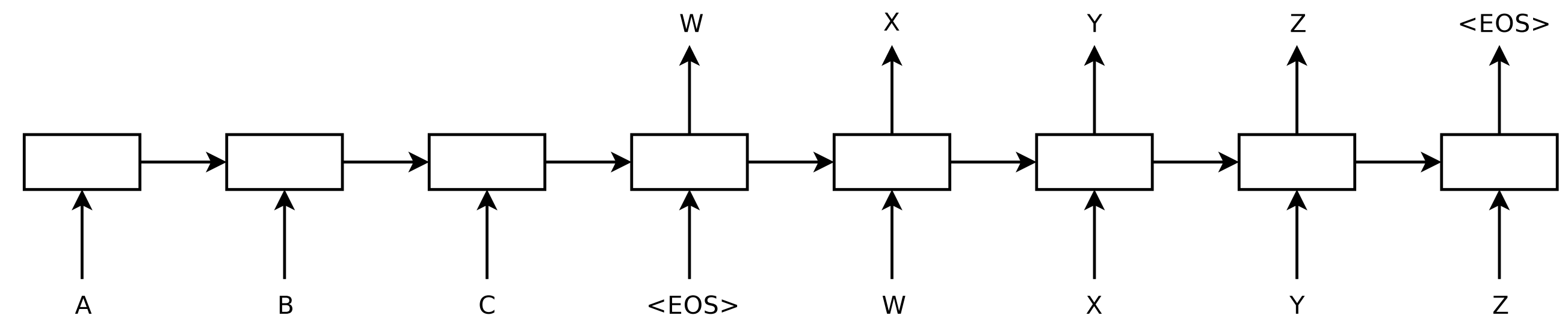
2014年,Sutskever等人提出了seq2seq,这是一种使用神经网络将一个序列映射到另一个序列的通用框架。在这个框架中,编码器神经网络逐个符号地处理一个句子,并将其压缩成向量表示;解码器神经网络根据编码器状态逐个预测输出符号,在每一步都以先前预测的符号作为输入,如下图所示。
机器翻译成为了该框架的杀手级应用。2016年,谷歌宣布开始用神经机器翻译模型(Wu et al.,2016)替换其基于短语的机器翻译模型。根据Jeff Dean的说法,这意味着用一个500行的神经网络模型代替了50万行的基于短语的机器翻译代码。
由于其灵活性,这个框架现在已成为自然语言生成任务的首选框架,不同的模型扮演编码器和解码器的角色。重要的是,解码器模型不仅可以基于序列进行条件化,还可以基于任意表示进行条件化。例如,在图像上生成标题(Vinyals et al., 2015)(如下图所示),根据表格生成文本(Lebret et al., 2016),以及根据源代码更改生成描述(Loyola et al., 2017)等许多其他应用。
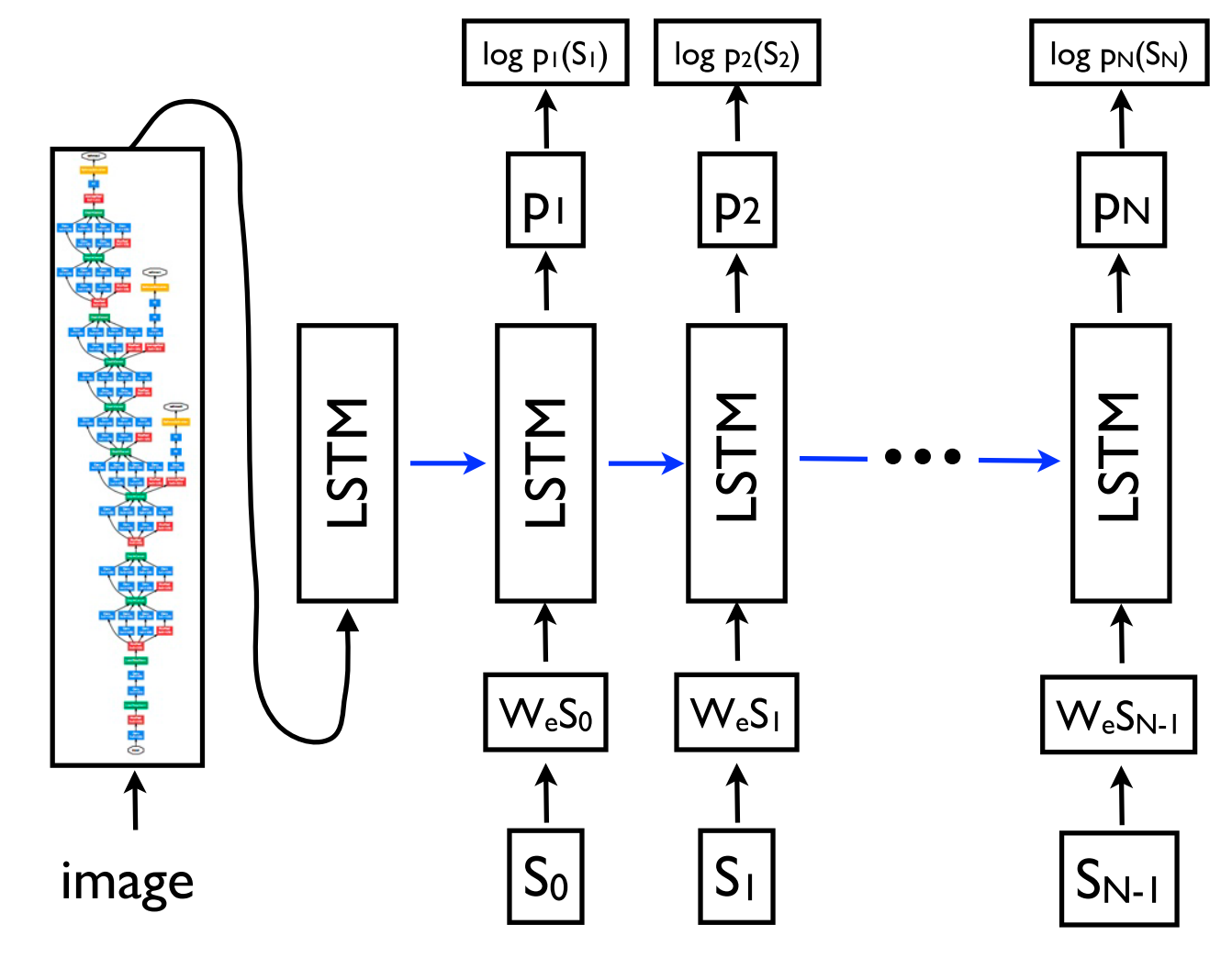
序列到序列学习甚至可以应用于NLP中常见的结构化预测任务,其中输出具有特定的结构。如下图简单的成分句法分析示例,可以看出输出被线性化了。神经网络已经证明了在给定足够数量的成分句法解析(Vinyals et al., 2015)和命名实体识别(Gillick et al., 2016)训练数据的情况下直接学习生成这种线性化输出的能力。
2015 - Attention
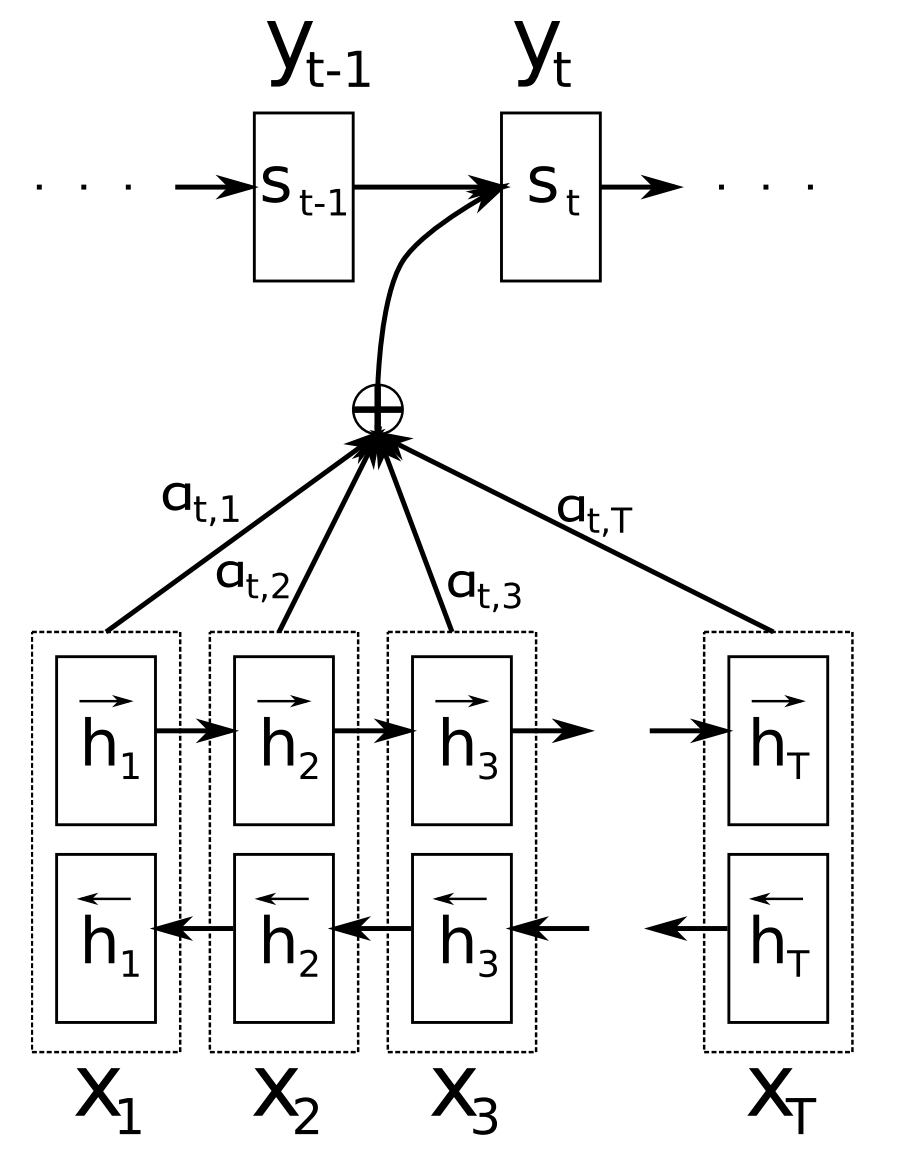
注意力机制(Bahdanau et al., 2015)是神经机器翻译(NMT)中的核心创新之一,也是使NMT模型胜过传统基于短语的机器翻译系统的关键思想。序列到序列学习的主要瓶颈在于需要将源序列的整个内容压缩成固定大小的向量。注意力通过允许解码器回顾源序列隐藏状态来缓解这个问题,然后将其作为加权平均值提供给解码器作为附加输入,如下图所示。
注意力机制广泛适用于任何需要基于输入的某些部分做出决策的任务,并具有潜在的实用价值。它已被应用于成分句法分析(Vinyals et al., 2015)、阅读理解(Hermann et al., 2015)和一次性学习(Vinyals et al., 2016)等许多领域。输入甚至不需要是一个序列,而可以由其他表示形式组成,如下图所示的图像字幕生成(Xu et al., 2015)。注意力机制的一个有用的副作用是通过检查注意权重来确定哪些输入部分与特定输出相关联,从而提供了对模型内部工作方式的一瞥。

注意力不仅限于查看输入序列;自注意力可以用来查看句子或文档中周围的单词,以获得更具上下文敏感性的单词表示。多层自注意是Transformer架构(Vaswani et al.,2017)的核心,这是当前最先进的NMT模型。
2015 - Memory-based networks
注意力可以被看作是一种模糊记忆形式,其中记忆由模型的过去隐藏状态组成,而模型选择从记忆中检索什么。关于注意力及其与记忆的联系的更详细概述,请查看此文章。已经提出了许多具有更明确内存的模型。它们有不同的变体,例如神经图灵机(Graves et al., 2014),记忆网络(Weston et al., 2015)和端到端内存网络(Sukhbaatar et al., 2015),动态内存网络(Kumar et al., 2015),神经可微分计算机(Graves et al., 2016)以及循环实体网络(Henaff et al., 2017)。
记忆通常是基于与当前状态的相似性进行访问,类似于注意力,并且通常可以进行写入和读取。模型在实现和利用内存方面存在差异。例如,端到端记忆网络多次处理输入并更新内存以实现多步推理。神经图灵机还具有基于位置的寻址功能,使它们能够学习简单的计算机程序,如排序。基于记忆的模型通常应用于需要保留信息更长时间跨度可能会有帮助的任务中,例如语言建模和阅读理解。记忆概念非常灵活:知识库或表格可以作为一种内存功能,而内存也可以根据整个输入或特定部分来填充。
2018 - Pretrained language models
预训练的词嵌入是与上下文无关的,仅用于初始化我们模型中的第一层。后来,一系列监督任务已被用来预训练神经网络(Conneau et al., 2017; McCann et al., 2017; Subramanian et al., 2018)。相比之下,语言模型只需要未标记的文本;因此可以扩展到数十亿个标记、新领域和新语言。
预先训练的语言模型最初是在2015年提出的(Dai&Le, 2015);直到18年才显示它们对各种任务都有益处。
语言模型嵌入可以用作目标模型(Peters et al., 2018)中的特征或者可以在目标任务数据上微调语言模型(Ramachandran et al., 2017; Howard&Ruder, 2018)。
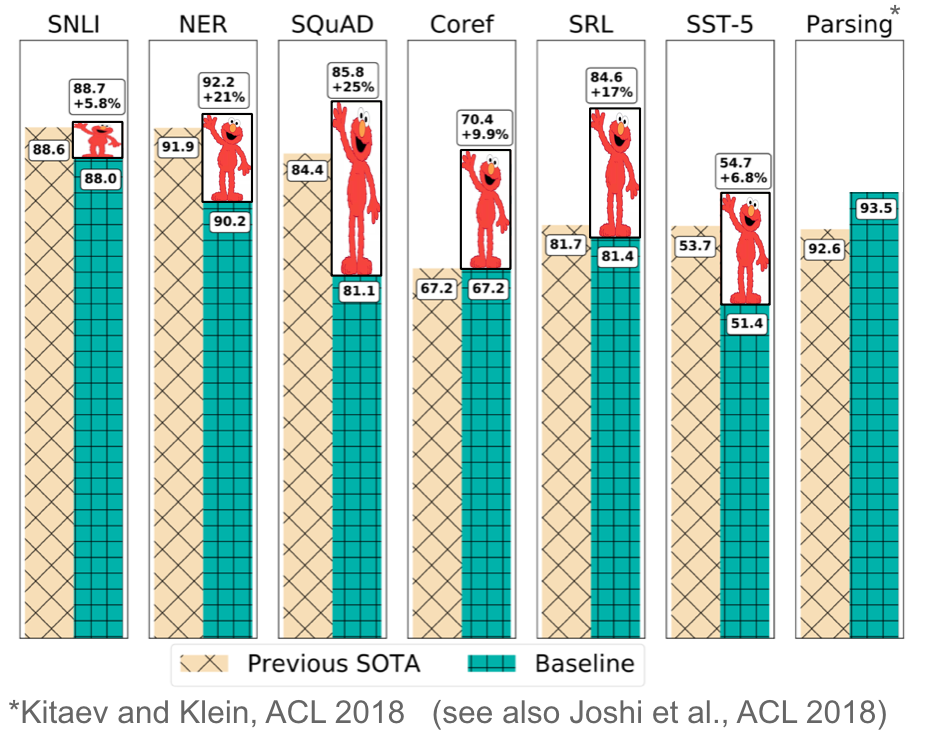
如下图所示,在许多不同任务中添加语言模型嵌入可大幅改善现有技术水平。
预训练语言模型被证明可以在使用更少数据的情况下进行学习。由于语言模型只需要无标签数据,因此它们对于标注数据稀缺的低资源语言尤其有益。
2018 - Large language models
如你所知,整个NLP领域发展到了LLMs时代。参考阅读《ChatGPT核心技术的进化之路》
结尾
GPT的提出标志着NLP技术的飞速发展,但对新手来说也增加了学习难度。要从头学习NLP,Claude给出了以下建议:
- 了解NLP基础知识。包括语言建模,词嵌入,神经网络,LSTM,Transformer等基础模型和技术。这些知识可以通过阅读《自然语言处理综述》等资料得到。
- 实现基本NLP任务的模型。如语言建模,文本分类,问答系统等。可以从简单的RNN和LSTM模型实现,了解基本思路和步骤。
- 理解Transformer和GPT等新模型。阅读论文《Attention is All You Need》和《Improving Language Understanding by Generative Pre-Training》,理解其模型结构,训练方法和创新点。
- 学习PyTorch和TensorFlow等深度学习框架。这些框架可以让你更容易实现复杂的NLP模型,对学习NLP模型很有帮助。
- 了解BERT,XLNet,RoBERTa等预训练语言模型。这些模型的使用和微调技巧需要理解,可以带来很大便利。
- 跟进NLP最新进展。阅读ACL,EMNLP,NAACL等顶会论文,了解最新的模型,技术和数据集。这可以让你了解NLP最新研究热点和前沿方向。
- 多练习和实现。上手实践是学习NLP最重要的方式之一。可以实现论文中的模型,优化和改进这些模型,并在各种数据集上进行试验。这可以加深理解和提高实践能力。
- 多阅读优质学习资料。像《神经网络与深度学习》《动手学深度学习》等书籍,全面且深入地介绍了深度学习和NLP相关知识。这些资料对学习NLP大有帮助。
总之,要系统和全面地学习NLP,需要理论与实践相结合。理解基础知识和最新研究进展,跟进理论前沿;并且要大量动手实践,通过实现和优化相关模型来加深理解。同时,也要利用优质学习资料,能够更全面和深入地学习这个领域的知识。持之以恒,NLP的学习之路才能走得更加通透。
- Blog Link: https://neo1989.net/Way2AI/Way2AI-neural-history-of-nlp/
- Copyright Declaration: 转载请声明出处。