GraphRAG:为生成式AI赋能知识
我们正步入RAG的“蓝色链接”时代
我们即将意识到,要想在生成式AI中做出显著有用的事情,不能仅仅依靠自回归大型语言模型来做决定。我知道你在想什么:“RAG是答案。”或者微调,或者GPT-5。
是的。向量基础的RAG和微调等技术可以有所帮助,并且对于某些使用场景来说已经足够好。但还有另一类使用场景,这些技术都会遇到瓶颈。向量基础的RAG——与微调一样——增加了许多类型问题正确答案的概率。然而,这两种技术都不能提供正确答案的确定性。它们常常也缺乏上下文、色彩以及与已知事实的联系。此外,这些工具不会告诉你为什么做出某个特定决定。
早在2012年,谷歌通过一篇标志性的博客文章“Introducing the Knowledge Graph: things, not strings”推出了第二代搜索引擎。他们发现,如果你使用知识图谱来组织这些网页中字符串所代表的事物,而不仅仅是处理字符串,能力会有巨大的飞跃。我们今天在生成式AI中看到了同样的模式。许多生成式AI项目都遇到了瓶颈,结果的质量受到使用的解决方案处理字符串而非事物的限制。
快进到今天,前沿的AI工程师和学术研究人员发现了与谷歌相同的事情:突破这个瓶颈的秘诀是知识图谱。换句话说,将关于事物的知识引入基于统计的文本技术组合中。这就像任何其他类型的RAG一样,只是除了向量索引,还调用了一个知识图谱。或者换句话说,就是GraphRAG!
这篇文章旨在对GraphRAG进行全面且易读的介绍。事实证明,构建你的数据知识图谱并在RAG中使用它会带来几个强大的优势。有大量研究表明,它能为你在使用普通向量基础的RAG向LLM提问时提供更好的答案。
仅这一点就将成为GraphRAG采纳的巨大驱动力。除此之外,由于在构建应用程序时数据是可见的,你会发现开发更容易。第三个主要优势是,图谱可以被人类和机器轻松理解和推理。因此,使用GraphRAG构建不仅更容易,能提供更好的结果,而且——在许多行业中这一点尤为重要——是可解释和可审计的!我相信GraphRAG将取代仅向量的RAG,并成为大多数使用场景中的默认RAG架构。这篇文章解释了为什么。
等等,Graph?
让我们明确一下,当我们说图时,我们指的是这样的东西:
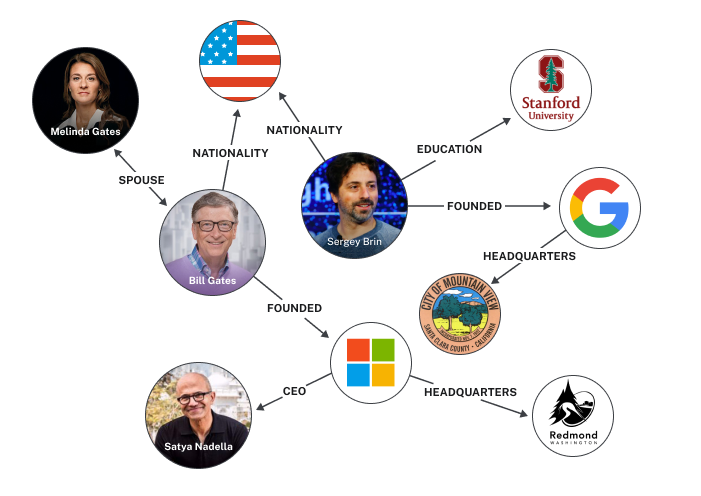
或者这个:
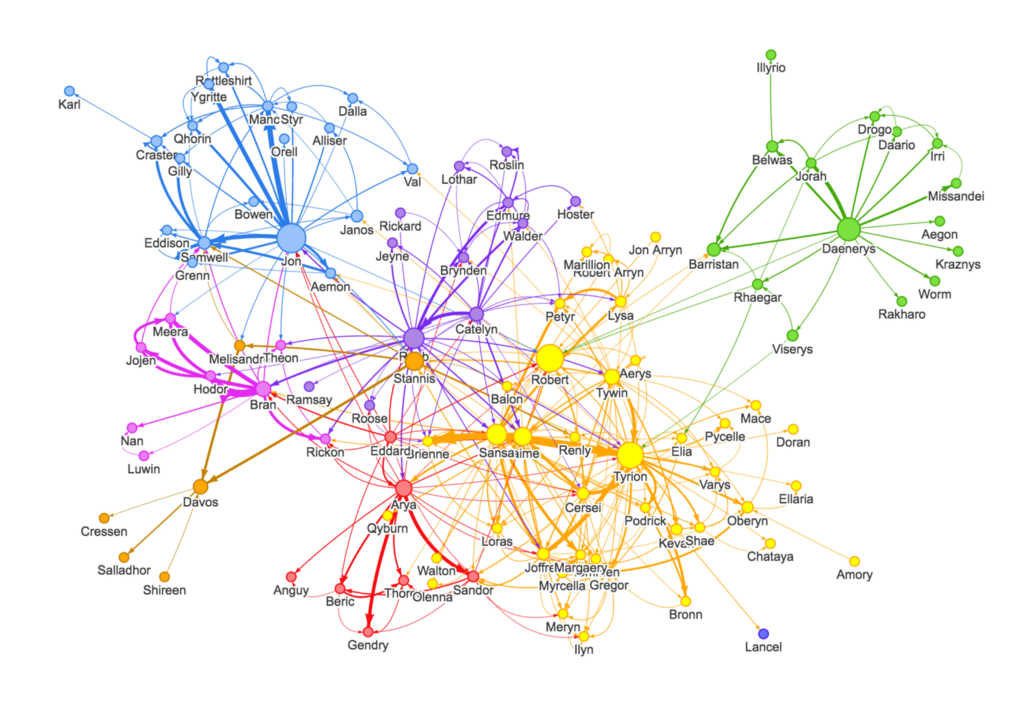
或者这个:
换句话说,它不是图表。
如果你想更深入地了解图和知识图谱,我推荐你去 Neo4j’s GraphAcademy 或Andrew Ng的Deeplearning.ai课程学习 Knowledge Graphs for RAG 。我们不会在这里停留在定义上,而是继续前进,假设你已经具备图的基本工作知识。
如果你理解上面的图片,你可以看到如何在RAG流程中查询底层知识图谱数据(存储在图数据库中)。这就是GraphRAG的核心。
两种知识表示方式:向量和图
典型RAG的核心——向量搜索——接收一段文本,并从候选书面材料中返回概念上相似的文本。这种方式既自动又神奇,对于基本搜索非常有用。
你可能不会每次都去思考向量的样子,或者相似性计算的具体过程。让我们来看一下苹果在人类术语、向量术语和图术语中的表示:

人类的表示方式是复杂且多维的,并不是我们能够完全在纸上捕捉到的。让我们稍加想象,把这张美丽诱人的图片视为苹果在其感知和概念上的全部荣耀。
苹果的向量表示是一个数字数组——统计领域的构造。向量的魔力在于它们以编码形式捕捉到其对应文本的精髓。然而,在RAG的背景下,它们只有在你需要识别一组词与另一组词的相似性时才有价值。这样做就像运行一个相似性计算(即向量数学)并得到匹配一样简单。但是,如果你想弄清楚向量内部的内容,理解它周围的内容,掌握文本中表示的事物,或者了解这些事物如何融入更大的背景,那么向量作为表示形式是无法做到的。
相比之下,知识图谱是声明性的——或者用AI术语来说,是符号化的——世界表示方式。结果是,人类和机器都可以理解和推理知识图谱。这是一个重大突破,我们稍后会再讨论。此外,你可以查询、可视化、注释、修复和扩展知识图谱。知识图谱代表你的世界模型——即你正在处理的领域的部分世界。
GraphRAG “vs.” RAG
这不是一场竞争🙂 向量和图查询在RAG中各自都有其价值。正如LlamaIndex创始人Jerry Liu所指出的那样,将GraphRAG视为包含向量是很有帮助的。这与“仅向量RAG”不同,后者严格基于文本中词语的嵌入相似性。
GraphRAG 模式
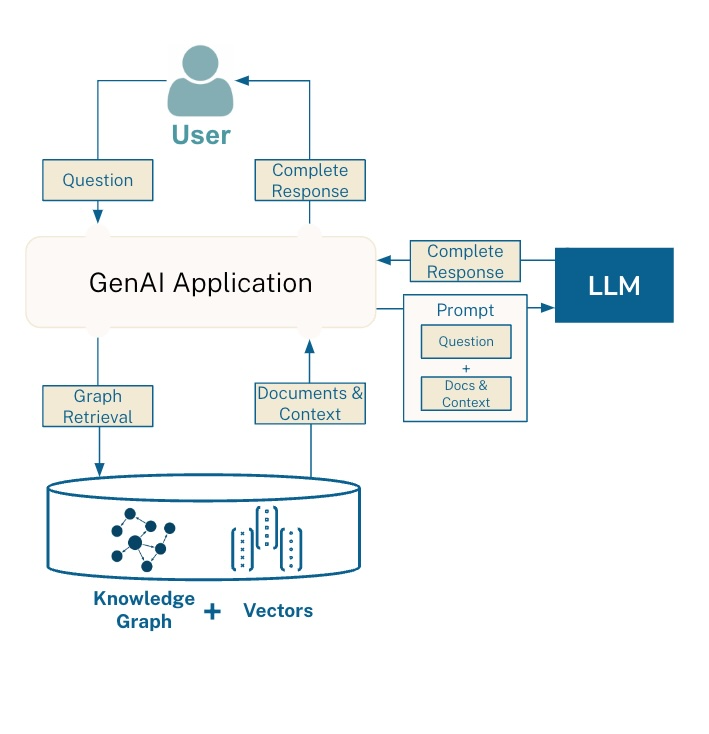
在这里,你会看到一个图查询被触发。它可以选择包含一个向量相似性组件。你可以选择将图和向量分别存储在两个独立的数据库中,或者使用像Neo4j这样的图数据库,它也支持向量搜索。
使用GraphRAG的常见模式之一如下:
- 进行向量或关键词搜索以找到初始节点集。
- 遍历图以带回有关相关节点的信息。
- 可选地,使用基于图的排序算法(如PageRank)重新排序文档。
模式因使用场景而异,和当今AI中的其他一切一样,GraphRAG正在证明它是一个丰富的领域,每周都有新发现。我们将在未来的博客文章中专门讨论今天看到的最常见的GraphRAG模式。
GraphRAG 生命周期
使用GraphRAG的生成式AI应用程序遵循与任何RAG应用程序相同的模式,但在开始时增加了一个“创建图”的步骤:
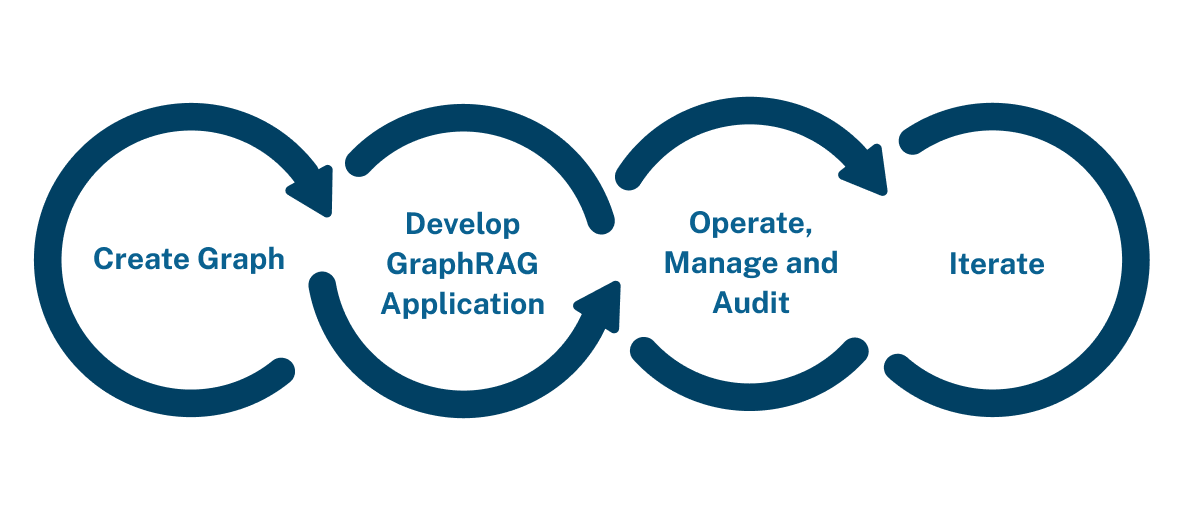
创建图类似于将文档分块并加载到向量数据库中。工具的进步已经使图的创建变得如此简单。好消息有三点:
- 图是高度迭代的——你可以从“最小可行图”开始,然后逐步扩展。
- 一旦你的数据在知识图谱中,进化就变得非常容易。你可以添加更多类型的数据,以获得数据网络效应的好处。你还可以提高数据质量,以提升应用程序结果的价值。
- 这一部分技术堆栈正在迅速改进,这意味着随着工具变得更复杂,图的创建将变得更容易。
将创建图的步骤添加到前面的图中,你将得到一个如下所示的流程:
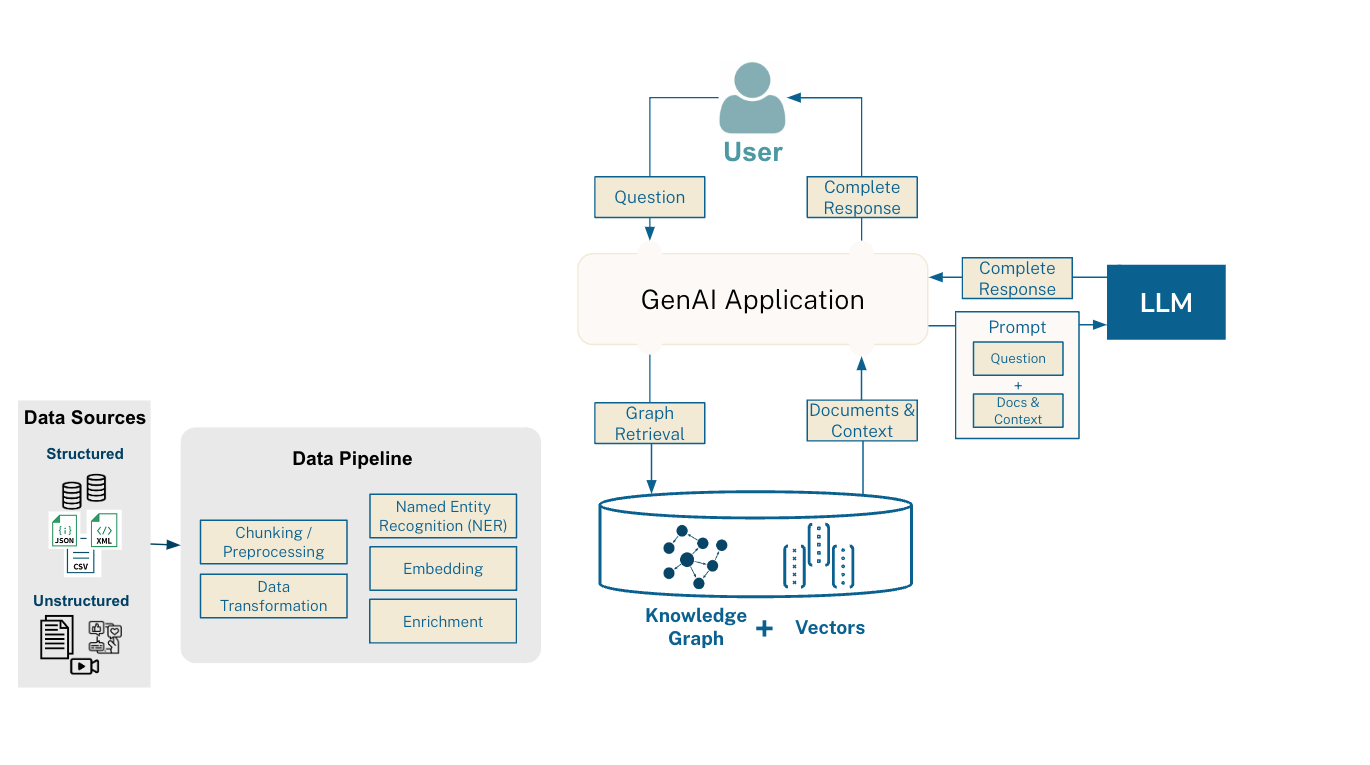
我稍后会深入探讨图谱的创建。现在,让我们先放下这个话题,来谈谈GraphRAG的好处。
为什么需要GraphRAG?
我们看到的GraphRAG相对于仅向量RAG的好处主要分为三个方面:
- 更高的准确性和更完整的答案(运行时/生产收益)
- 一旦创建了知识图谱,构建和随后维护你的RAG应用程序就变得更容易(开发时间收益)
- 更好的可解释性、可追溯性和访问控制(治理收益)
知识图谱的创建
人们经常问我构建知识图谱需要什么。要理解这个问题的答案,首先需要了解与生成型人工智能应用最相关的两种图谱:
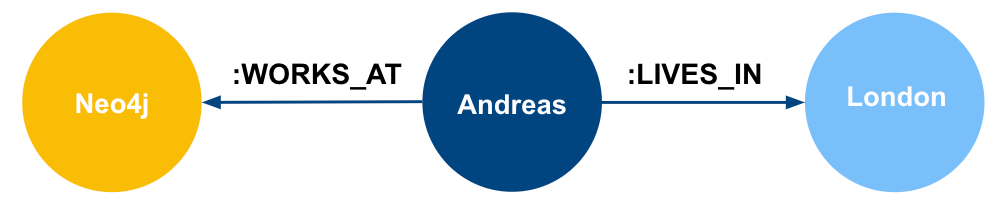
- 领域图是与您的应用相关的世界模型的图形表示。以下是一个简单的例子:
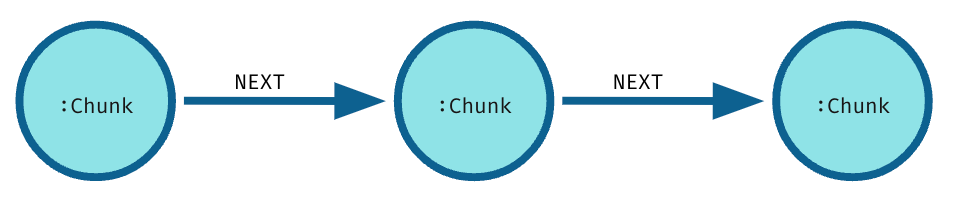
- 词汇图是文档结构的图形表示。最基本的词汇图为每一段文本设置一个节点:
人们常常将词汇图扩展,以包括文本段落与文档对象(如表格)、章节、部分、页码、文档名称/ID、集合、来源等之间的关系。您还可以将领域图和词汇图结合起来,如下所示:
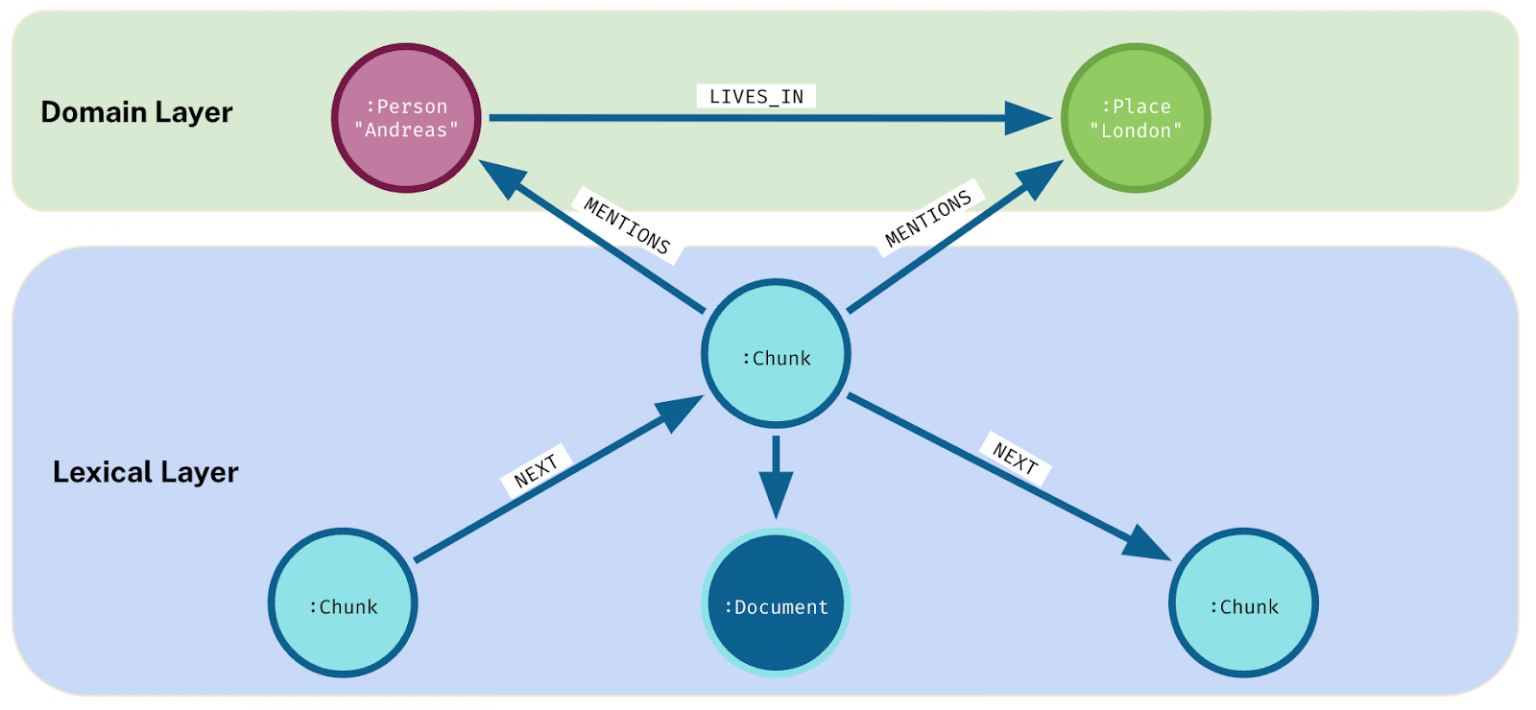
创建词汇图相对简单,主要是通过解析和分块策略来实现。对于领域图的创建,则需要根据数据来源的不同选择相应的方法,无论是结构化数据、非结构化文本,还是两者结合。幸运的是,从非结构化数据源创建知识图谱的工具正在迅速改进。比如,新的Neo4j知识图谱构建器能够将PDF文档、网页、YouTube视频片段或维基百科文章自动转换为知识图谱。只需点击几个按钮,就能可视化(当然也可以查询)输入文本的领域图和词汇图。这既强大又有趣,大大降低了创建知识图谱的门槛。
关于客户、产品、地理等数据,可能以结构化形式存在于您的企业某处,并可以直接从其存储位置获取。最常见的情况是这些数据存在于关系数据库中,可以使用标准工具根据成熟的关系到图映射规则进行处理。
使用知识图谱
一旦你有了知识图谱,就有越来越多的框架可以用来进行GraphRAG,包括LlamaIndex Property Graph Index、Langchain的Neo4j集成以及Haystack等。这个领域发展迅速,现在编程方法已经变得简单明了。
在图谱构建方面也是如此,有诸如Neo4j Importer这样的工具,它提供了一个用于将表格数据映射和导入到图谱中的图形界面,还有前面提到的Neo4j的新v1 LLM知识图谱构建器。下图总结了构建知识图谱的步骤。
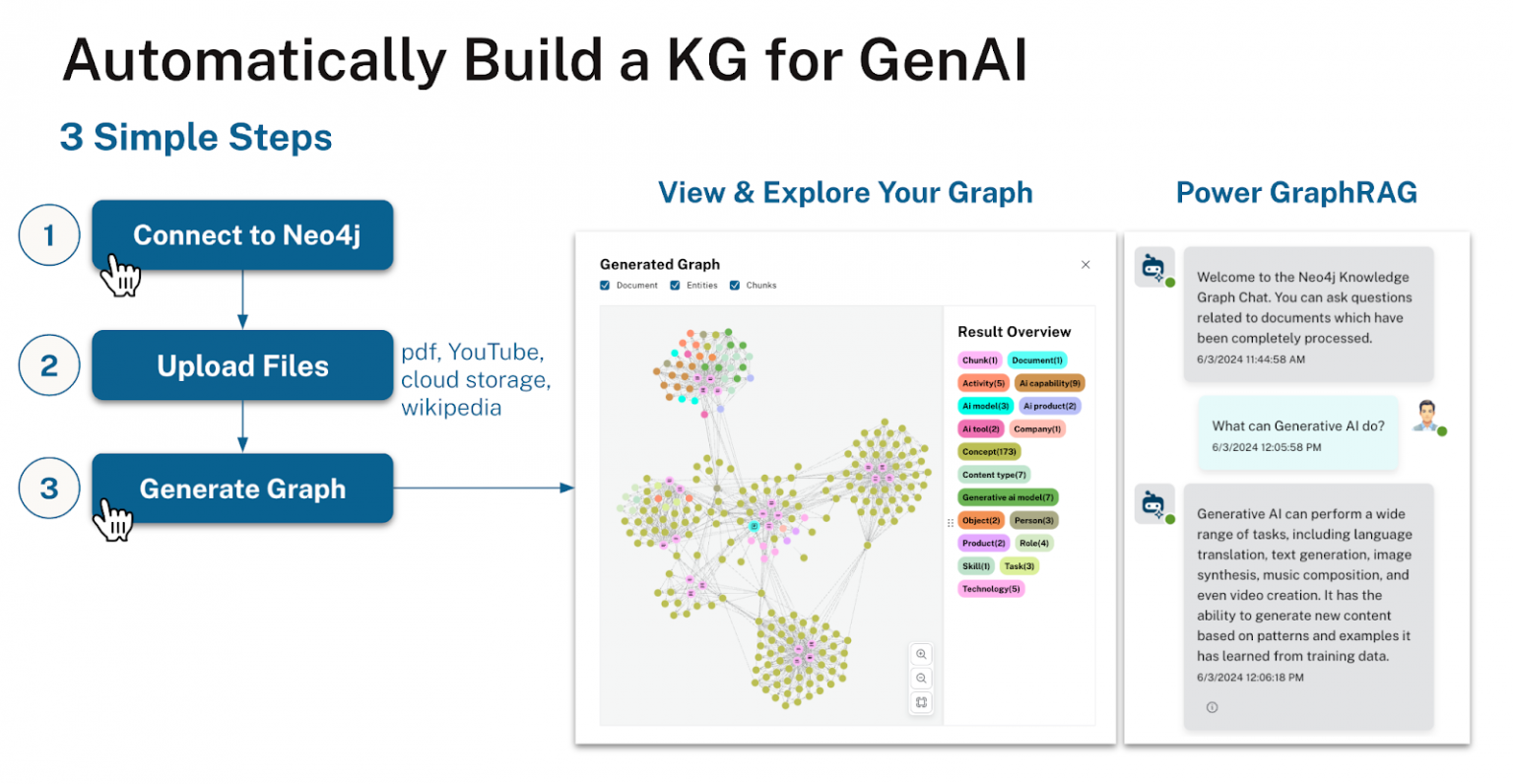
在使用知识图谱时,你会发现另一件需要做的事情是将人类语言的问题映射到图数据库查询。Neo4j推出的一款新的开源工具NeoConverse,就是为了帮助自然语言查询图谱而设计的。这是朝着普及这一技术迈出的坚实第一步。
虽然开始使用图谱确实需要一些工作和学习,但好消息是,随着工具的改进,这变得越来越容易。
GraphRAG 是 RAG 的下一个自然发展步骤
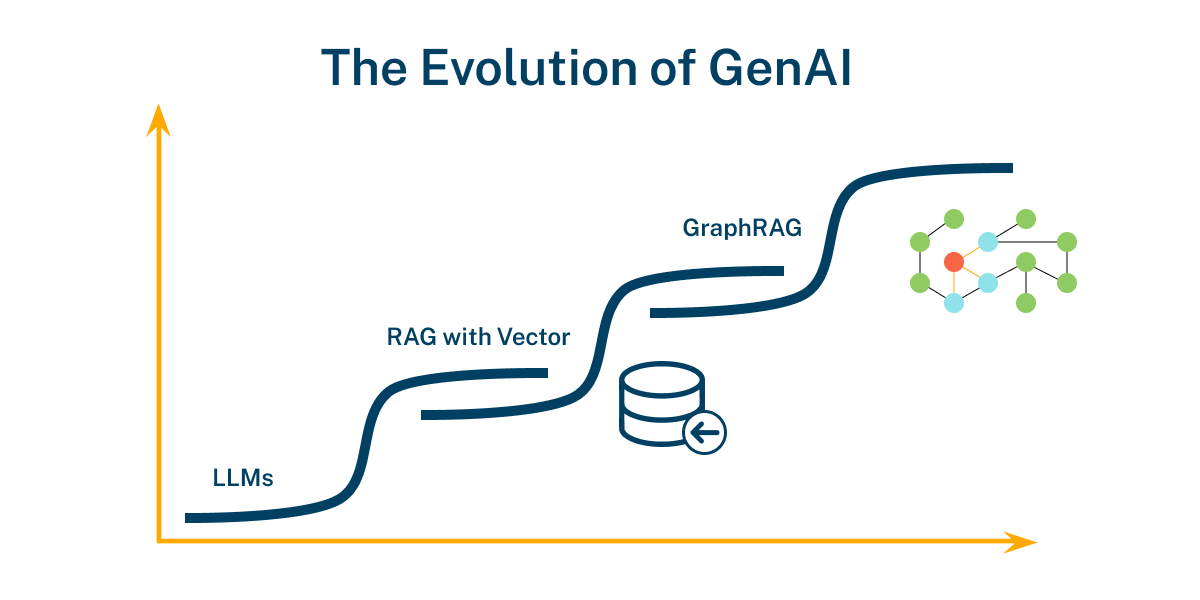
LLM 和基于向量的 RAG 中固有的单词计算和语言技能提供了不错的结果。要获得始终如一的出色结果,需要超越字符串,不仅捕捉单词模型,还要捕捉世界模型。就像谷歌发现要掌握搜索,需要超越纯文本分析并绘制出字符串背后的基本内容一样,我们在 AI 领域也开始看到相同的模式。这种模式就是 GraphRAG。
进步以 S 曲线的形式发生:当一项技术达到顶峰时,另一项技术推动进步,并超越前者。随着生成型 AI 的进步,在那些答案质量至关重要的应用中;或内部、外部或监管利益相关者需要可解释性时;或需要对数据隐私和安全进行细粒度控制时,您的下一个生成型 AI 应用很可能会使用知识图谱。
- Blog Link: https://neo1989.net/Way2AI/Way2AI-GraphRAG/
- Copyright Declaration: 转载请声明出处。